这个实验书上的示例是6台机器(虚拟机),我在本机部署时由于内存原因只用了4台虚拟机,但效果还是基本达到了,只有在模拟某台管理节点宕机时,出现剩下的唯一一个管理节点无法正常工作的情况(和使用raft共识有关),在对应部分会详细说明。
本次实验的环境是4台Ubuntu18.04虚拟机,每台2G内存、1核2线程,采用桥接模式共用宿主机网络。
Docker Swarm
Swarm有两层含义:
- 一个Docker安全集群:让用户以集群方式管理一个或多个Docker节点,默认内置分布式集群存储,加密网络,公用TLS,安全集群接入令牌,简化的数字证书管理PKI。
- 一个微服务编排引擎:通过声明式配置文件部署和管理复杂的微服务应用,支持滚动升级,回滚,以及扩缩容。
Swarm中的节点分为管理节点和工作节点:
- 管理节点:负责集群的控制,监控集群状态,分发任务到工作节点。
- 工作节点:接收任务并执行。
搭建Swarm集群
初始化Swarm
在正式搭建之前,每个节点需要开放下面的端口:
- 2377/tcp:用于客户端与Swarm安全通信。
- 7946/tcp与7946/udp:用于控制面gossip分发。
- 4789/udp:用于基于VXLAN的覆盖网络
我用iptables完成了这些步骤。下面开始创建集群。
初始化Swarm
不包含在Swarm中的Docker节点称为运行于单引擎模式,一旦加入Swarm就切换为Swarm模式。首先通过docker swarm init将第一个节点切换到Swarm模式并设置其为第一个管理节点A。
lzl@lzl:~$ docker swarm init \
> --advertise-addr 10.0.20.25:2377 \ # 其他节点用来连接当前管理节点的IP和端口
> --listen-addr 10.0.20.25:2377 # 承载Swarm流量的IP和端口
Swarm initialized: current node (kwtw0ybgf4uzd1d6bcdpwze1y) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-2avftcvr1a1lesoqcyjr06tdvjvvof9n0wiz39lepv8aezk6xm-2dai3bks4siwhgetlhcuqnonz 10.0.20.25:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
Swarm给出提示,向集群加入新的管理节点和工作节点需要什么命令,它们需要的token是不同的,比如加入管理节点的命令:
lzl@lzl:~$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join --token SWMTKN-1-2avftcvr1a1lesoqcyjr06tdvjvvof9n0wiz39lepv8aezk6xm-erhmvcq8z52aure635nv6w8ch 10.0.20.25:2377
下面加入一个工作节点C
lzl@lzl-c:~$ docker swarm join --token SWMTKN-1-2avftcvr1a1lesoqcyjr06tdvjvvof9n0wiz39lepv8aezk6xm-2dai3bks4siwhgetlhcuqnonz 10.0.20.25:2377 \
> --advertise-addr 10.0.20.26:2377 \ # 这两个属性虽然是可选的
> --listen-addr 10.0.20.26:2377 # 但是最好指明每个节点的网络属性
This node joined a swarm as a worker.
加入其他节点
同样的,我们把第二个管理节点B和第二个工作节点D加入集群。
lzl@lzl-b:~$ docker swarm join --token SWMTKN-1-2avftcvr1a1lesoqcyjr06tdvjvvof9n0wiz39lepv8aezk6xm-erhmvcq8z52aure635nv6w8ch 10.0.20.25:2377 \
> --advertise-addr 10.0.20.35:2377 \
> --listen-addr 10.0.20.35:2377
This node joined a swarm as a manager.
lzl@lzl-d:~$ docker swarm join --token SWMTKN-1-2avftcvr1a1lesoqcyjr06tdvjvvof9n0wiz39lepv8aezk6xm-2dai3bks4siwhgetlhcuqnonz 10.0.20.25:2377 \
> --advertise-addr 10.0.20.27:2377 \
> --listen-addr 10.0.20.27:2377
This node joined a swarm as a worker.
这样我们集群中就有了:
管理节点A:10.0.20.25
管理节点B:10.0.20.35
工作节点C:10.0.20.26
工作节点D:10.0.20.27
查看集群中的节点
lzl@lzl:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
aez7db9rdqoylqktrk7stcu49 lzl-c Ready Active 20.10.10
jfhjtedzu8mg0y6vzgw0unvw7 lzl-d Ready Active 20.10.10
kwtw0ybgf4uzd1d6bcdpwze1y * lzl Ready Active Leader 20.10.10
ppvj0ll2jo0smt4htpms9fosw lzl-b Ready Active Reachable 20.10.10
Swarm已经启动TLS以保证集群安全。
- *:表示当前节点
- Leader:表示管理节点的Leader
- Reachable:表示其他可用的管理节点
高可用性HA
Swarm使用Raft达成共识,我这里使用两个管理节点实际上是不好的,一个是数量太少,另一个是偶数个管理节点可能发生脑裂现象。最好是部署奇数个管理节点,也不要太多,3个5个都行。
即使一个或多个管理节点出现故障,其他管理节点也会继续工作保证Swarm的运转。管理节点中的主节点是唯一的会对Swarm发送控制命令的节点,其他管理节点收到的命令会转发给主节点。
安全机制
Swarm的安全机制如CA、接入Token、公用TLS、加密网络、加密集群存储、加密节点ID等开箱即用。
锁定Swarm
Docker提供了自动锁机制锁定Swarm,使得重启的管理节点只有提供集群解锁码后才能重新接入集群。
在管理节点A启用锁:
lzl@lzl:~$ docker swarm update --autolock=true
Swarm updated.
To unlock a swarm manager after it restarts, run the `docker swarm unlock`
command and provide the following key:
SWMKEY-1-0A98dswMx4EOOmfMwjlVDEL1w1OLncMAQniYV+nPKuk
Please remember to store this key in a password manager, since without it you
will not be able to restart the manager.
重启另一个管理节点B,发现它加不进去,因为集群上锁了:
lzl@lzl-b:~$ service docker restart
lzl@lzl-b:~$ docker node ls
Error response from daemon: Swarm is encrypted and needs to be unlocked before it can be used. Please use "docker swarm unlock" to unlock it.
我们在管理节点A列出节点试试?
lzl@lzl:~$ docker node ls
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
由于部署2个管理节点,1个节点掉线后,仅剩的管理节点A无法正常工作,因为要求至少半数管理节点在线,所以为什么至少要3、5个管理节点。
现在用解锁key启动管理节点B:
lzl@lzl-b:~$ docker swarm unlock
Please enter unlock key: SWMKEY-1-0A98dswMx4EOOmfMwjlVDEL1w1OLncMAQniYV+nPKuk
lzl@lzl-b:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
aez7db9rdqoylqktrk7stcu49 lzl-c Ready Active 20.10.10
jfhjtedzu8mg0y6vzgw0unvw7 lzl-d Ready Active 20.10.10
kwtw0ybgf4uzd1d6bcdpwze1y lzl Ready Active Leader 20.10.10
ppvj0ll2jo0smt4htpms9fosw * lzl-b Ready Active Reachable 20.10.10
Swarm服务
Docker1.12后引入服务,通过Swarm部署服务的多个实例,实现服务的高可用、弹性、滚动升级。
我们部署一个简单的Web服务:
lzl@lzl:~$ docker service create --name web-fe \
> -p 8080:8080 \
> --replicas 3 \
> nigelpoulton/pluralsight-docker-ci
image nigelpoulton/pluralsight-docker-ci:latest could not be accessed on a registry to record
its digest. Each node will access nigelpoulton/pluralsight-docker-ci:latest independently,
possibly leading to different nodes running different
versions of the image.
cz5m15yzyfzvxoilx2czv9s0n
overall progress: 3 out of 3 tasks
1/3: running
2/3: running
3/3: running
verify: Service converged
- –replicas:表示有3个实例
假设某个节点宕机了,服务实例降为2个,那么Swarm会再实例化一个服务,保证有3个实例提供服务。通过端口映射,每个机器上访问8080端口都可以访问服务。
查看Swarm服务
列出服务:
lzl@lzl:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
cz5m15yzyfzv web-fe replicated 3/3 nigelpoulton/pluralsight-docker-ci:latest *:8080->8080/tcp
查看每个服务副本:
lzl@lzl:~$ docker service ps web-fe
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
mexucdagzhx3 web-fe.1 nigelpoulton/pluralsight-docker-ci:latest lzl-b Running Running about a minute ago
if2hnpkawwhk web-fe.2 nigelpoulton/pluralsight-docker-ci:latest lzl-c Running Running about a minute ago
mtkhx4uaazya web-fe.3 nigelpoulton/pluralsight-docker-ci:latest lzl-d Running Running about a minute ago
查看该服务细节:
lzl@lzl:~$ docker service inspect --pretty web-fe
ID: cz5m15yzyfzvxoilx2czv9s0n
Name: web-fe
Service Mode: Replicated
Replicas: 3
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: nigelpoulton/pluralsight-docker-ci:latest
Init: false
Resources:
Endpoint Mode: vip
Ports:
PublishedPort = 8080
Protocol = tcp
TargetPort = 8080
PublishMode = ingress
- –pretty:不加会列出更为详细的信息。
副本服务和全局服务
- 副本模式:这是默认的模式,将期望数量的副本均匀的分布到整个集群中。
- 全局模式:每个节点上仅运行一个副本,使用
docker create service --mode global部署全局模式。
服务扩缩容
假设3个实例提供服务有些吃力了,我们需要将实例增加到6个。
lzl@lzl:~$ docker service scale web-fe=6
web-fe scaled to 6
overall progress: 6 out of 6 tasks
1/6: running [==================================================>]
2/6: running [==================================================>]
3/6: running [==================================================>]
4/6: running [==================================================>]
5/6: running [==================================================>]
6/6: running [==================================================>]
verify: Service converged
lzl@lzl:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
cz5m15yzyfzv web-fe replicated 6/6 nigelpoulton/pluralsight-docker-ci:latest *:8080->8080/tcp
lzl@lzl:~$ docker service ps web-fe
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
mexucdagzhx3 web-fe.1 nigelpoulton/pluralsight-docker-ci:latest lzl-b Running Running 7 minutes ago
if2hnpkawwhk web-fe.2 nigelpoulton/pluralsight-docker-ci:latest lzl-c Running Running 7 minutes ago
mtkhx4uaazya web-fe.3 nigelpoulton/pluralsight-docker-ci:latest lzl-d Running Running 7 minutes ago
ngjcu26etj9l web-fe.4 nigelpoulton/pluralsight-docker-ci:latest lzl Running Running about a minute ago
4muhlzldan91 web-fe.5 nigelpoulton/pluralsight-docker-ci:latest lzl-c Running Running about a minute ago
m4ugu5sz63b8 web-fe.6 nigelpoulton/pluralsight-docker-ci:latest lzl-d Running Running about a minute ago
Swarm自动为我们均衡的增加了服务实例,现在再将实例降回到3个。
lzl@lzl:~$ docker service scale web-fe=3
web-fe scaled to 3
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
lzl@lzl:~$ docker service ps web-fe
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
mexucdagzhx3 web-fe.1 nigelpoulton/pluralsight-docker-ci:latest lzl-b Running Running 10 minutes ago
if2hnpkawwhk web-fe.2 nigelpoulton/pluralsight-docker-ci:latest lzl-c Running Running 10 minutes ago
mtkhx4uaazya web-fe.3 nigelpoulton/pluralsight-docker-ci:latest lzl-d Running Running 10 minutes ago
ngjcu26etj9l web-fe.4 nigelpoulton/pluralsight-docker-ci:latest lzl Remove Running 9 seconds ago
4muhlzldan91 web-fe.5 nigelpoulton/pluralsight-docker-ci:latest lzl-c Remove Running 9 seconds ago
m4ugu5sz63b8 web-fe.6 nigelpoulton/pluralsight-docker-ci:latest lzl-d Remove Running 9 seconds ago
现在有3个服务实例已经被移除。
删除服务
lzl@lzl:~$ docker service rm web-fe
web-fe
滚动升级
下面用一个新的服务演示滚动升级。在此之前,需要创建一个覆盖网络overlay。这是一个二层网络,所有接入该网络的容器可以互相通信,即使这些容器的宿主机的底层网络不同。
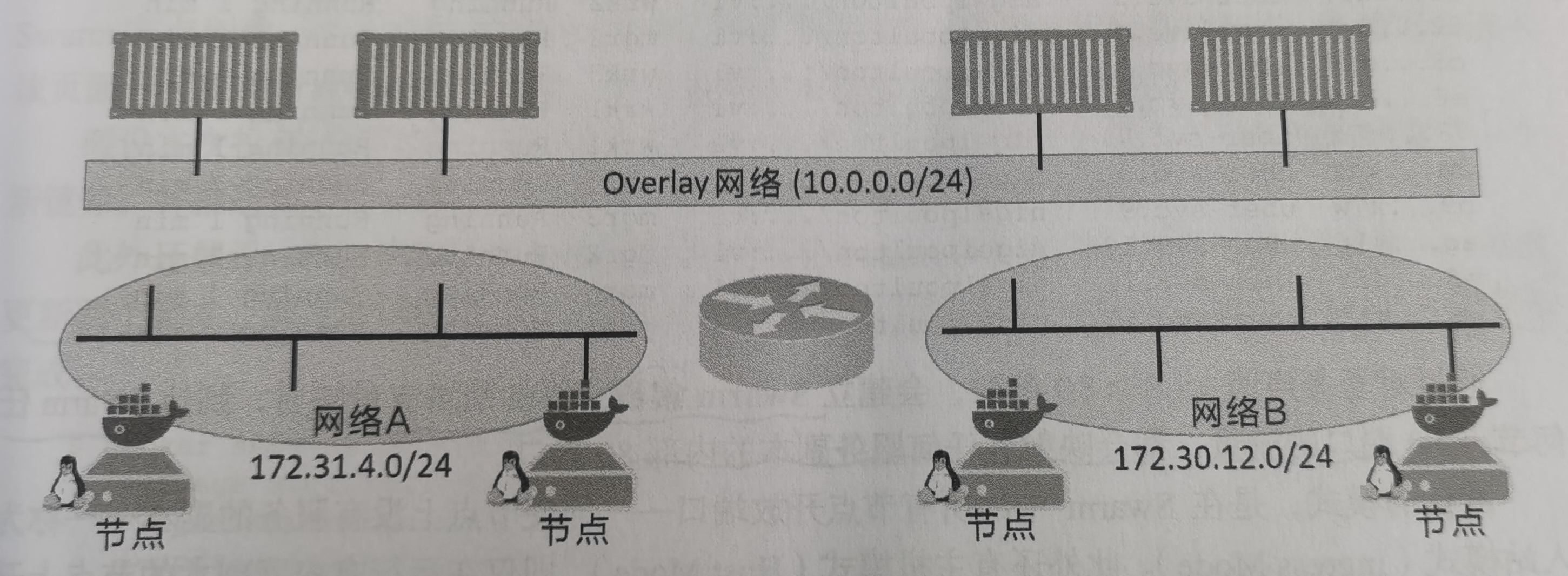
lzl@lzl:~$ docker network create -d overlay uber-net
np6r4rhm4lpsalikwfiahopcy
lzl@lzl:~$ docker network ls
NETWORK ID NAME DRIVER SCOPE
72f99c88c853 bridge bridge local
9027fdbdc8f6 docker_gwbridge bridge local
7a84b4fa35eb host host local
mvd937imkve6 ingress overlay swarm
66b37b687b76 none null local
np6r4rhm4lps uber-net overlay swarm # 我们新建的覆盖网络
然后新建一个服务,创建8个服务提供实例,并把它接入该网络。
lzl@lzl:~$ docker service create --name uber-svc \
> --network uber-net \
> -p 80:80 --replicas 8 \
> nigelpoulton/tu-demo:v1
image nigelpoulton/tu-demo:v1 could not be accessed on a registry to record
its digest. Each node will access nigelpoulton/tu-demo:v1 independently,
possibly leading to different nodes running different
versions of the image.
v5hohnigjlubbg7itg42habfr
overall progress: 8 out of 8 tasks
1/8: running [==================================================>]
2/8: running [==================================================>]
3/8: running [==================================================>]
4/8: running [==================================================>]
5/8: running [==================================================>]
6/8: running [==================================================>]
7/8: running [==================================================>]
8/8: running [==================================================>]
verify: Service converged
lzl@lzl:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
v5hohnigjlub uber-svc replicated 8/8 nigelpoulton/tu-demo:v1 *:80->80/tcp
lzl@lzl:~$ docker service ps uber-svc
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
3cxuushzkvo4 uber-svc.1 nigelpoulton/tu-demo:v1 lzl-c Running Running 49 seconds ago
xjv8k31yxhxt uber-svc.2 nigelpoulton/tu-demo:v1 lzl-b Running Running 49 seconds ago
xzxyzyk9kxy9 uber-svc.3 nigelpoulton/tu-demo:v1 lzl-c Running Running 48 seconds ago
tg6zmzqwzab6 uber-svc.4 nigelpoulton/tu-demo:v1 lzl-d Running Running 52 seconds ago
y4jl7yg5jsc1 uber-svc.5 nigelpoulton/tu-demo:v1 lzl Running Running 49 seconds ago
s8yvzixgbepo uber-svc.6 nigelpoulton/tu-demo:v1 lzl-d Running Running 50 seconds ago
69ghlllr9mi5 uber-svc.7 nigelpoulton/tu-demo:v1 lzl-b Running Running 48 seconds ago
mtkg9y3j7dl3 uber-svc.8 nigelpoulton/tu-demo:v1 lzl Running Running 51 seconds ago
-p 80:80:把所有到达Swarm节点的80端口的流量映射到每个服务副本中的80端口--network uber-net:服务的所有副本使用这个覆盖网络
一般的,对于开放端口的处理,默认使用入站模式,此外还有主机模式。
- 入站模式:所有Swarm节点都开放端口,即使节点上没有任何服务副本,从任何节点的IP都可以访问到服务,因为节点配置的映射会将请求转发给有服务实例的节点
- 主机模式:仅在运行了服务实例的节点开放端口
下面来看滚动升级,升级策略是每次升级2个副本,间隔20秒。
lzl@lzl:~$ docker service update \
> --image nigelpoulton/tu-demo:v2 \
> --update-parallelism 2 \
> --update-delay 20s uber-svc
image nigelpoulton/tu-demo:v2 could not be accessed on a registry to record
its digest. Each node will access nigelpoulton/tu-demo:v2 independently,
possibly leading to different nodes running different
versions of the image.
uber-svc
overall progress: 2 out of 8 tasks
1/8: running [==================================================>]
2/8: running [==================================================>]
3/8:
4/8:
5/8:
6/8:
7/8:
8/8:
--image nigelpoulton/tu-demo:v2:指定升级的服务镜像--update-parallelism 2:每次升级2个服务--update-delay 20s:升级间隔20秒
在升级过程中,我们查看当前服务实例副本:
lzl@lzl:~$ docker service ps uber-svc
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
3cxuushzkvo4 uber-svc.1 nigelpoulton/tu-demo:v1 lzl-c Running Running 6 minutes ago
mc36cqxnh0gs uber-svc.2 nigelpoulton/tu-demo:v2 lzl-b Running Running 37 seconds ago
xjv8k31yxhxt \_ uber-svc.2 nigelpoulton/tu-demo:v1 lzl-b Shutdown Shutdown 39 seconds ago
nok5eng7umqc uber-svc.3 nigelpoulton/tu-demo:v2 lzl-c Running Running 11 seconds ago
xzxyzyk9kxy9 \_ uber-svc.3 nigelpoulton/tu-demo:v1 lzl-c Shutdown Shutdown 13 seconds ago
dkxz1gpg4f4f uber-svc.4 nigelpoulton/tu-demo:v2 lzl-d Running Running 37 seconds ago
tg6zmzqwzab6 \_ uber-svc.4 nigelpoulton/tu-demo:v1 lzl-d Shutdown Shutdown 39 seconds ago
flgey27vyz35 uber-svc.5 nigelpoulton/tu-demo:v2 lzl Running Running 11 seconds ago
y4jl7yg5jsc1 \_ uber-svc.5 nigelpoulton/tu-demo:v1 lzl Shutdown Shutdown 13 seconds ago
s8yvzixgbepo uber-svc.6 nigelpoulton/tu-demo:v1 lzl-d Running Running 6 minutes ago
69ghlllr9mi5 uber-svc.7 nigelpoulton/tu-demo:v1 lzl-b Running Running 6 minutes ago
mtkg9y3j7dl3 uber-svc.8 nigelpoulton/tu-demo:v1 lzl Running Running 6 minutes ago
在滚动升级的过程中,同时存在新版本的服务和旧版本的服务。在这个时候去访问网站,可能会出现有的访问的是新的服务有的访问的是旧的服务。但升级期间我们的服务仍然是正常工作的,在滚动升级完成后,所以服务实例都被升级。
故障排除
排障这部分主要是通过Swarm集群工作日志来实现的。
lzl@lzl:~$ docker service logs uber-svc
uber-svc.8.mtkg9y3j7dl3@lzl | [2021-11-15 08:03:19 +0000] [1] [INFO] Starting gunicorn 20.1.0
uber-svc.8.mtkg9y3j7dl3@lzl | [2021-11-15 08:03:19 +0000] [1] [INFO] Listening at: http://0.0.0.0:80 (1)
uber-svc.8.mtkg9y3j7dl3@lzl | [2021-11-15 08:03:19 +0000] [1] [INFO] Using worker: sync
uber-svc.8.mtkg9y3j7dl3@lzl | [2021-11-15 08:03:19 +0000] [6] [INFO] Booting worker with pid: 6
uber-svc.8.mtkg9y3j7dl3@lzl | [2021-11-15 08:03:19 +0000] [7] [INFO] Booting worker with pid: 7
uber-svc.8.mtkg9y3j7dl3@lzl | [2021-11-15 08:03:19 +0000] [8] [INFO] Booting worker with pid: 8
uber-svc.8.mtkg9y3j7dl3@lzl | [2021-11-15 08:03:19 +0000] [9] [INFO] Booting worker with pid: 9
uber-svc.8.mtkg9y3j7dl3@lzl | [2021-11-15 08:10:54 +0000] [1] [INFO] Handling signal: term
···
退出Swarm模式
最后,我们down掉服务后,退出Swarm模式,将集群关闭。
# 在工作节点上使用
lzl@lzl:~$ docker swarm leave
Node left the swarm.
# 在管理节点上使用
lzl@lzl:~$ docker swarm leave --force
Node left the swarm.