最近有跟进学习爬虫的知识,教材是《Python网络数据采集》(Ryan Mitchell),之后配合《利用Python进行数据分析》(Wes McKinney)进一步学习,我想学习路线也不会很长或者说很陡峭。昨天在B站找了北理工的爬虫慕课,我觉得这个课程对于初学者非常友好,今天就copy一个小玩意纯当入门。
先上代码
# 这是一个未封装的示例,需要的话可以封装成函数接口,或者做一下用户界面用Pyinstaller做个小工具。
# 我觉得可以,但是没必要哈
import requests
import os
url = "https://jdvodrvfb210d.vod.126.net/mooc-video/nos/mp4/2016/06/19/1004550079_f7311774e53d4771b7069623b4728b97_hd.mp4"
root = "D://pics//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
详解
B站上有好多up主有搬运的mooc的视频,我想很多油猴插件也是用类似的方法将网站上的视频搬运到更方便的地方的。
今天爬取中国大学mooc上的一个视频,外加LonelyPlanet(孤独星球是我高中时非常喜欢的杂志)一张图片作为示例。
# 引入的包
import requests
import os
requests 是一个python自带的库,适用于小型(mini可以)爬虫
我们用os库的方法创建文件夹和存放下载的文件
url = "https://jdvodrvfb210d.vod.126.net/mooc-video/nos/mp4/2016/06/19/1004550079_f7311774e53d4771b7069623b4728b97_hd.mp4"
root = "D://pics//"
path = root + url.split('/')[-1]
url 存放我们所爬取信息的url链接,一般来说,图片文件是以“ .jpg ” 结尾的,而视频文件是以 “ .mp4 ”结尾的。(当然不止这两种,一般是图片或者视频常用的后缀比如:png mkv等等等)
root 存放的是下载后文件的存放路径,代码是以 D 盘的 pics 文件夹作为根目录。
path 是具体文件的存放路径,split 这个方法是将字符串以 “/” 为分隔,生成列表,取最后一项,举个栗子:
url = "https://123/456/goodnight.jpg"
root = "D://pics//"
path = root + url.split('/')[-1]
# 这样的话, path = D:/pics/goodnight.jpg
# 打开D盘的pics文件夹就能看到goodnight.jpg这个文件了
try:
if not os.path.exists(root): # 如果没有这个根目录
os.mkdir(root)
if not os.path.exists(path): # 如果没有这个文件,我们就可以下载,不会产生异常
r = requests.get(url)
with open(path, 'wb') as f: # 基本的文件操作
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
try _ except 块是最基础的框架,可套用。
开动
首先是mooc的小视频
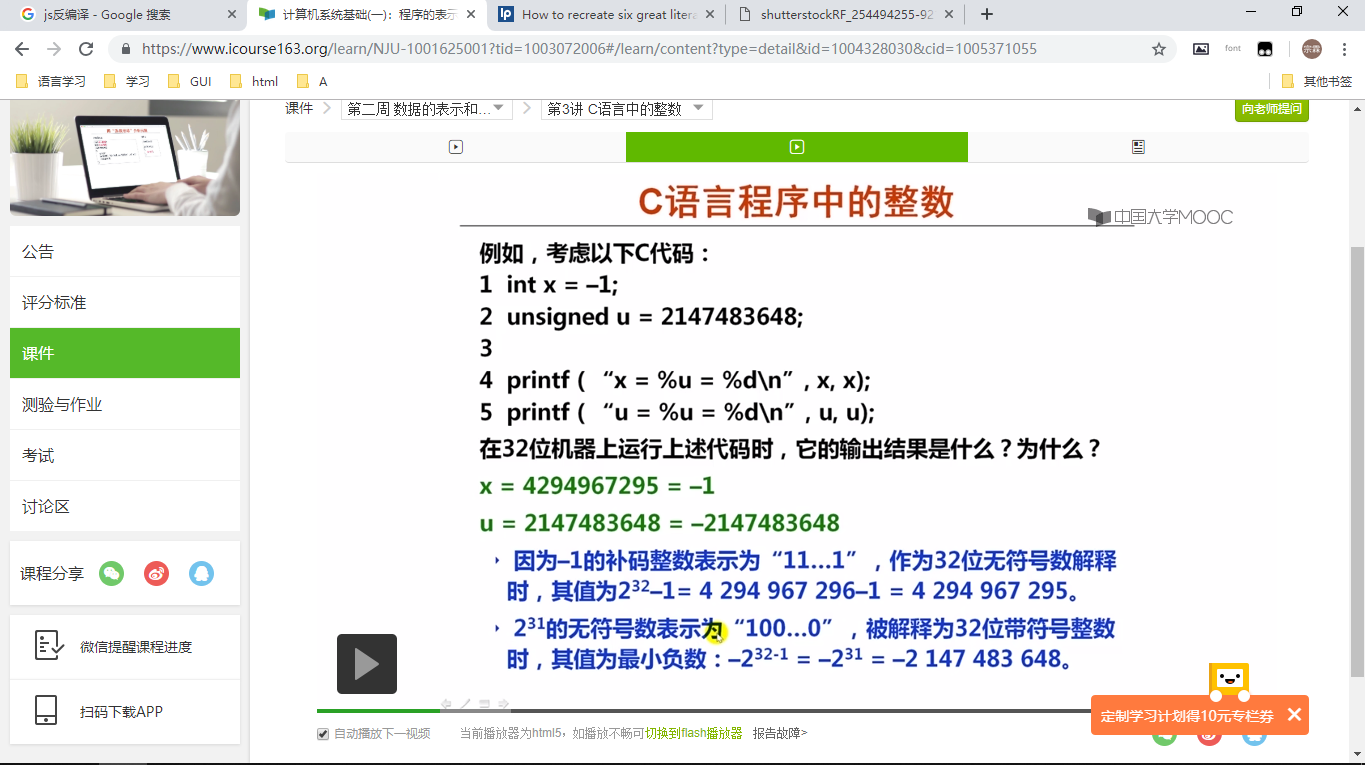
我就用这个吧(袁春风老师讲的计组确实不错~),那么怎么找到视频的url链接呢,我们右键视频
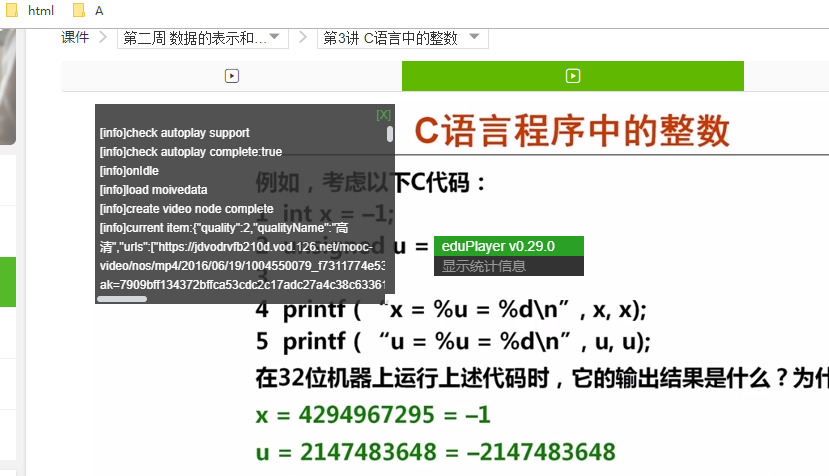
在显示统计信息里,我们看到了url 相关的字样,这是有效信息,将它搞下来(Chrome浏览器提供开发者工具应该也可以的)
尽可能多的将全部url信息复制下来,ctrl C V好像没用,直接拖出来吧
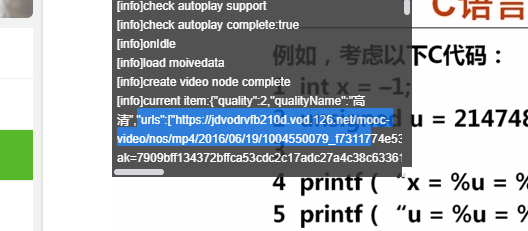

然后提取有用信息

我们只需要 http ~ mp4 之间的,也就是

好了,放到 url 里面
url = "https://jdvodrvfb210d.vod.126.net/mooc-video/nos/mp4/2016/06/19/1004550079_f7311774e53d4771b7069623b4728b97_hd.mp4"
运行,如果没出现异常,下载文件是需要等一会的o
感人网速下了一分多钟,差点以为挂掉了

然后打开D盘发现生成pics文件夹并且下载好了
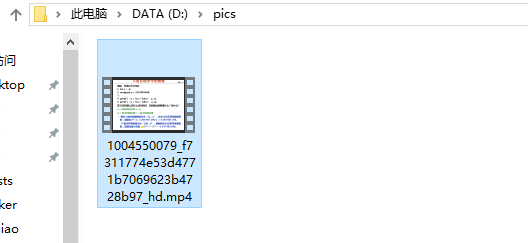
win10截屏快捷键是 win + shift + s,自动保存在剪切板,直接ctrl v用就行了
图片的也是一样,理论上只要能得到url链接就可以。