来源:SoCC'21
Meiklejohn C S, Estrada A, Song Y, et al. Service-Level Fault Injection Testing[C]//Proceedings of the ACM Symposium on Cloud Computing. 2021: 388-402.
摘要
越来越多的企业使用微服务架构发布他们的大规模的移动或是Web应用。
问题在于,并非所有系统开发人员都有分布式系统的管理经验,由于这些大规模的应用多是部署与分布式系统中,所以在生产环境中的故障很有可能在开发环境中不会出现。一旦这些微服务部署在分布式系统中,就有可能出现故障。所以,一种好的解决方法就是尽早找出这些问题:在测试环境或者在代码交付生产前就将其解决。
本文提出服务级别故障注入测试,并实现一个原型“filibuster”,用来系统的识别开发环境中微服务的弹性问题。“Filibuster”使用静态分析及并发风格的执行,还有新颖的动态缩减算法,来扩展现有功能测试的套件,减少开发人员的工作。
为了证明工具的适用性,文章展示了4个包含错误的真实工业微服务应用程序的语料库。数据来自大公司生产中运行的实验公开信息。文章展示了实验如何在开发过程中运行,并在投入生产环境之前就检测到错误。
前置知识
1. 混沌工程
在本文中,多次讲到“chaos engineering”,在我个人理解,混沌工程是本文的“服务级故障注入测试”的基础,或者说是“上一个版本”。
混沌工程代表项目,Netflix创建的“Chaos Monkey”可以在系统的随机位置引发故障,可以随时终止生产环境中运行的虚拟机和容器实例。通过“Chaos Monkey”,开发者可以快速了解构建的服务的健壮性,是否可以弹性扩容以及处理意外故障。
参考:知乎-系统架构设计之路
混沌工程,是一种提高技术架构弹性能力的复杂技术手段。Chaos工程经过实验可以确保系统的可用性。混沌工程旨在将故障扼杀在襁褓之中,也就是在故障造成中断之前将它们识别出来。通过主动制造故障,测试系统在各种压力下的行为,识别并修复故障问题,避免造成严重后果。
主要针对于分布式系统上的故障测试。
1.1 混沌工程与故障注入的区别
混沌工程是一种生成新信息的实践,而故障注入是测试一种情况的一种特定方法。
1.2 混沌工程实验的步骤
通常混沌工程由以下四个步骤组成。
- 定义测试系统的“稳定状态”。精确定义指标,表明系统按照应有的方式运行。 Netflix使用客户点击视频流设备上播放按钮的速率作为指标,称为“每秒流量”。请注意,这更像是商业指标而非技术指标;在混沌工程中,业务指标通常比技术指标更有用,因为它们更适合衡量用户体验或运营。
- 创建假设。与任何实验一样,您需要一个假设来进行测试。因为你试图破坏系统正常运行时的稳定状态,你的假设将是这样的,“当我们做X时,这个系统的稳定状态应该没有变化。”为什么用这种方式表达?如果你的期望是你的动作会破坏系统的稳定状态,那么你会做的第一件事会是修复问题。混沌工程应该包括真正的实验,涉及真正的未知数。
- 模拟现实世界中可能发生的事情,目前有如下混沌工程实践方法:模拟数据中心的故障、强制系统时钟不同步、在驱动程序代码中模拟I/O异常、模拟服务之间的延迟、随机引发函数抛异常。通常,您希望模拟可能导致系统不可用或导致其性能降低的场景。首先考虑可能出现什么问题,然后进行模拟。一定要优先考虑潜在的错误。 “当你拥有非常复杂的系统时,很容易引起出乎意料的下游效应,这是混沌工程寻找的结果之一,”“因此,系统越复杂,越重要,它就越有可能成为混沌工程的候选对象。”
- 证明或反驳你的假设。将稳态指标与干扰注入系统后收集的指标进行比较。如果您发现测量结果存在差异,那么您的混沌工程实验已经成功 - 您现在可以继续加固系统,以便现实世界中的类似事件不会导致大问题。或者,如果您发现稳定状态可以保持,那么你对该系统的稳定性大可放心。
1.3 案例
https://github.com/chaos-mesh/chaos-mesh
https://github.com/chaosblade-io
Into
混沌测试(一种用于生产环境中的错误注入,来模拟在用户角度的服务bug)已经证明了的可行性。本文要做的就是把这个过程放在更早的阶段——在开发阶段就检测到这些错误。
现在又有这样的问题:缺少开源的微服务应用。仅有的开源微服务应用仅仅用来展示如何构建这些微服务应用,并没有展示这些应用在开发、部署时会出现什么错误。因此,该研究不得不和公司合作,并且需要签订严格的保密措施。
本文贡献
- 提出一种微服务测试方法:服务级别的故障注入测试
- 一种新的动态归约算法:将应用程序分解成独立的微服务来减少搜索空间的组合爆炸
- 实现了这个服务级别的故障注入测试方法——Filibuster:基于Python开发,可以测试提供HTTP通信的微服务
- 一个用Python实现的微服务应用和故障的语料库:包含8个小心微服务应用程序,每个应用程序都展示了微服务应用中使用的单一模式;还有4个从公开会议演讲中的工业级应用实例——Audible、Expedia、Mailchimp、Netflix
- 并通过该语料库对Filibuster做出评价:表明Filibuster可以用于识别语料中的所有错误,并且展示了通过动态减少可能进行的优化,还提供了如何设计微服务应用程序以实现可测试性的见解。
挑战——应对
目前困难主要在于:
- 缺少开源的工业级微服务应用案例和相关的错误报告。而这两个内容是软件推动软件测试领域的主要语料库。
- 现有的一些的对于软件测试的研究都是基于一些开源的bug数据库和开源社区的软件,问题在于,这些软件架构多是单体架构,而故障也不是微服务架构所特有的。所以,需要有微服务应用特有的故障以供研究。
- 而对于大型的微服务应用提供商,往往不能直接去研究。这些产品往往是企业的核心,一般不会开源,并且内部的漏洞也不会公开。
所以,文章系统回顾了50个关于混沌工程的演讲,从这些公开的视频中寻找案例。这些公开演讲中的公司主要关注两个问题:
-
开发中的软件的可靠性
-
运行这些软件的基础设施的稳定性
进一步团队根据下面的条件寻找语料:
- 演讲中是否提供了使用混沌工程发现的真正的详细错误信息
- 所展示的混沌工程是否可以在本地复现(也就是在非生产环境中进行混沌测试)
最终,文章选取了4个案例,它们来自 Audible、Expedia、Mailchimp和Netflix。
| 案例来源 | 服务类型 | 使用混沌工程发现的问题简述 |
|---|---|---|
| Audible | 有声读物移动应用 | 代码中未处理的错误,该错误会通过通用错误消息传播传到移动客户端 |
| Expedia | 旅游预订服务 | 基于相关性排序的酒店评价服务不可用,回退到基于时间排序的 |
| Mailchimp | 电子邮件管理应用 | 两处不处理返回错误的问题 |
| Netflix | 流媒体应用 | 1.加载客户主页设计的服务故障;2.配置错误超时;3.服务回退失败;4.关键服务未配置回退策略 |
技术细节
架构示意图
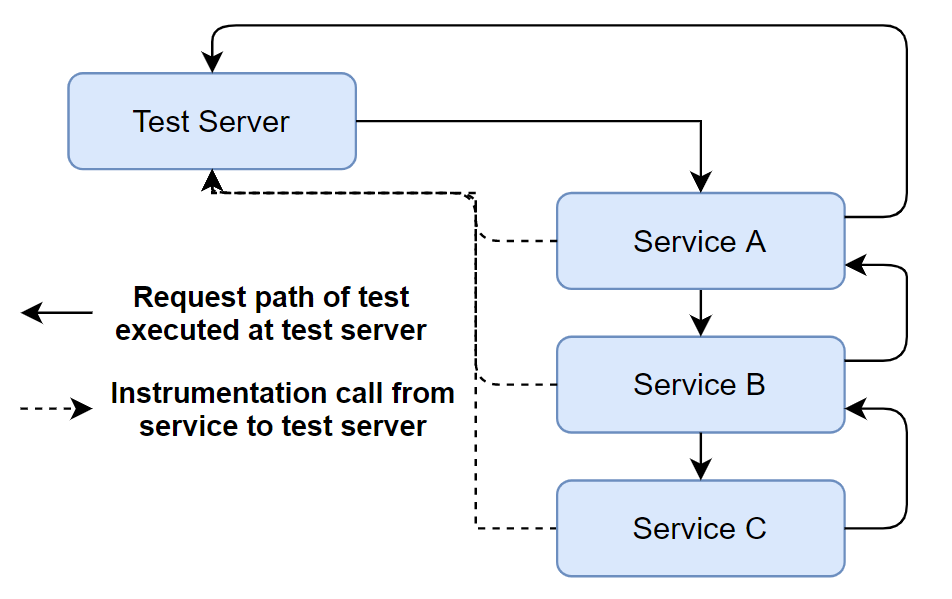
对每个测试服务器进行检测调用,识别调用从何处发起,从何处接收,并在测试期间注入故障。考虑上图,服务A调用服务B,然后服务B调用服务C,最后将结果返回。
SFIT(Service-Level Fault Injection Testing )建立在当今微服务程序开发的三个关键点之上:
- 微服务是独立开发的:不同微服务开发团队难以知晓其他团队服务的内部细节和详细使用规范,难以验证其他服务的问题
- 如果对于微服务进行故障模拟测试,能很大程度上保证生产环境下服务正常运行:但是从文章选取的案例来看,许多团队并没有这样做,可能是因为这样耗费时间或者性价比太低
- 功能测试是黄金标准:开发者使用端到端的测试,并认为这是非常有用的, 本文也因此也在这一点切入。
SFIT实现细节
假设服务通过HTTP提供,并且单个功能测试可以测试所有应用程序行为。
Overview
- 通过常规测试,排除服务的逻辑错误。
- 在两个微服务的通信端点,再设计一个测试,并且对微服务之间的请求进行错误注入。如果这次错误注入可以引起不同的服务错误,那么对于每种错误都再复现一次。
- 这些后续的执行放在堆栈上,然后递归执行,直到探索到所有的问题点。
故障注入
本文的方法依赖于远程调用,如HTTP或gRPC,因此需要有干预微服务之间请求的能力。Opentelemetry、Opentracing等工具已经提供了远程通信的公共调用库。利用这种工具设计故障注入:根据注入的故障,返回故障响应。
故障识别
- 发起请求调用源点的故障:例如Python中request库执行HTTP请求时,执行该请求会引发23个异常,本演示只考虑两个最常见的故障——超时和连接错误。
- 接收请求的远程服务的故障:如果一个服务依赖的另一个服务抛出Timeout异常,那么调用它的服务可能会捕获到,并返回500。
此外,还有一点是,HTTP请求使用URL标识。相似的URL可能用于不同的服务,所以需要对调用的服务进行一个标识,以此明确服务调用双方的身份。
测试适配
本文提供了一个模块帮助开发者编写故障注入测试,从而减轻开发人员编写复杂测试的负担。需要注意,本文的测试是非入侵的。
故障缩减
如果组成应用有几十上百的微服务,那么出现错误的空间将非常大。所以有必要在实现故障最大覆盖率的同时,减少搜索空间,提高效率。利用服务分解,对每个独立的微服务进行排障。
为此,我们可以利用以下 3 个关键观察结果:
- 充分了解服务依赖项可能失败的所有方式。确保我们了解单个服务的一个或多个依赖项失败时的行为以及该服务返回的结果失败是什么。参考图Audible示例,探索 ADS 依赖项可能失败的方式组合(以及 CDS 依赖项失败的方式等)
- 如果我打算在两个或多个不同服务的至少一个依赖项上注入故障,我们已经知道这些故障将对将它们作为依赖项的服务产生的影响。以图Audible示例,我们已经知道当 ADS 的依赖项以任何可能的组合失败时会返回什么,因为我们已经运行了该测试。我们也已经知道当 CDS 的依赖项出于同样的原因以任何可能的组合失败时,它会返回什么。因此,我们不必在依赖项处注入故障,直接在 ADS 或 CDS 中直接注入适当的响应。
- 如果我们已经在该服务中注入了该故障,那么测试就是多余的,因为我们已经观察到了应用程序的这种行为。如果我们参考图Audible示例,我们不需要测试 Stats 服务失败与 Audio Assets 或 Audio Metadata 服务的失败,因为我们已经知道这些失败的结果,这些服务将它们作为依赖;我们也已经观察到这些结果。
动态归约算法

Filibuster
这是该团队实现的原型,利用Python以及一些开源库实现的。
Filibuster可以注入这些故障:
- 调用端异常:由请求库抛出,指示连接错误或超时等条件。对于所有异常类型,Filibuster 可以在抛出异常之前有条件地联系其他服务。对于超时,Filibuster 可以在抛出超时异常之前有条件地等待超时时间。
- 错误响应:从远程服务使用标准 HTTP 错误代码指示内部服务器错误或服务不可用等情况。对于每个错误代码,Filibuster 可以有条件地返回一个关联的正文。
由于 Filibuster 是作为服务器编写的,跨语言支持是可能的,但尚未实现。仪器和 Filibuster 服务器之间的所有通信都是通过独立于语言的协议进行的;任何特定于语言的东西都在仪器库中完成。
应用语料库
电影应用案例
由四个微服务组成:
- 放映时间:返回电影的放映时间
- 电影:返回给定电影的信息
- 预订:给定用户名,返回有关该用户预订的信息
- 用户:存储用户信息并通过首先请求用户的预订来编排来自最终用户的请求,并且对于每个预订执行对电影服务的后续请求以获取有关电影的信息
根据上述的基础案例,文章又改造了7个示例:
- Cinema-2:直接预定电影
- Cinema-3:与cinema-2 相同,但users 服务在调用bookings 服务时有一个重试循环
- Cinema-4:与cinema-2 相同,但每个服务在发出任何请求之前都与外部服务对话:用户服务向IMDB 发出请求;预订服务向 Fandango 提出请求;电影服务向 Rotten Tomatoes 提出请求
- Cinema-5:无论失败与否,所有请求都会发生;在失败的情况下,使用硬编码的默认响应。
- Cinema-6:添加了预订的第二个副本,在主要副本出现故障时联系该副本。
- Cinema-7:与cinema-6 相同,但用户服务在发出实际请求之前调用主要预订副本上的健康检查端点。
- Cinema-8:示例被折叠成单体,其中 API 服务器通过重试循环向它发出请求
工业级案例Audible、Expedia、Mailchimp 和 Netflix
示例并不是要重现这些公司的整个微服务架构:我们只关注他们执行的特定混沌实验中涉及的服务。
Audible
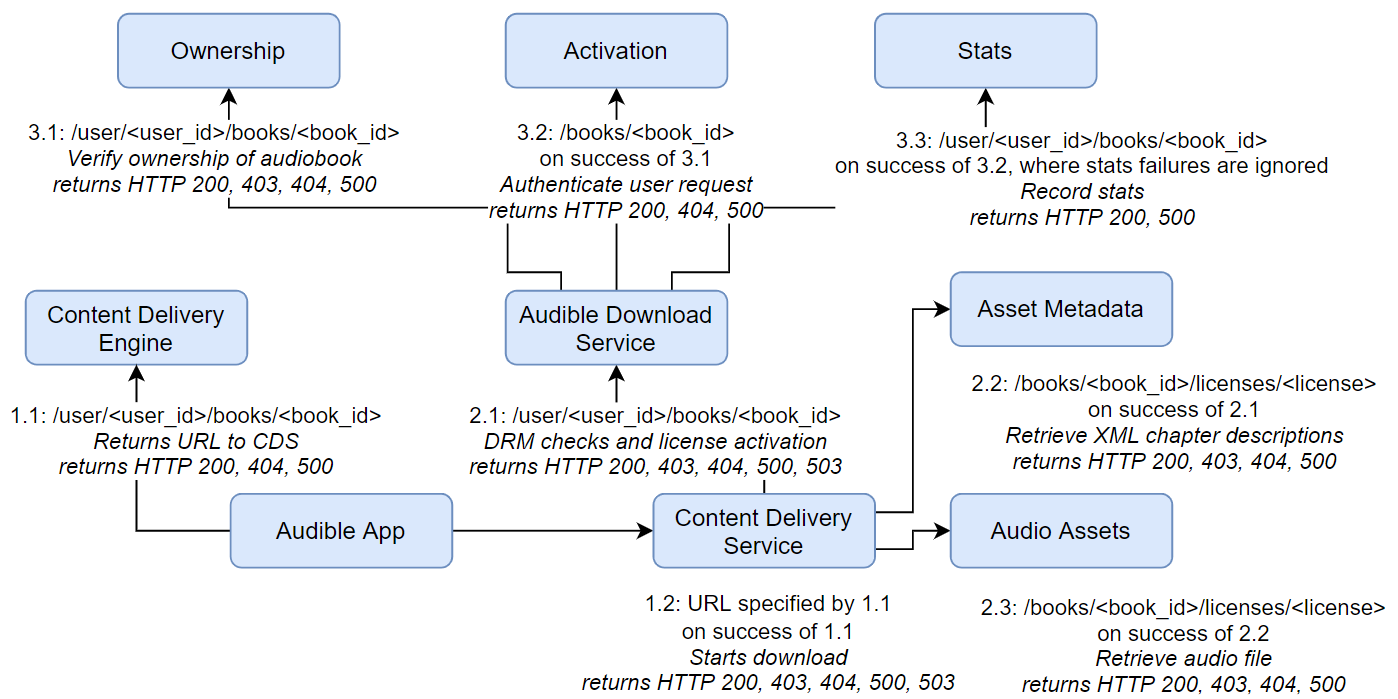
这个案例包含8个微服务和一个移动客户端:
- 内容交付服务(CDS):给定图书标识符和用户标识符,授权后返回实际音频内容和音频元数据
- 内容交付引擎 (CDE):返回要请求的的正确 CDS 的 URL
- Audible App:模拟移动应用程序,向CDE发出请求,根据图书标识符查找相应CDS实例的URL,然后向其发出请求
- 声音下载服务(ADS):一旦所有权得到验证,就会协调日志记录和 DRM 授权
- 所有权:验证书的所有权
- 激活:为用户激活 DRM 许可证
- 统计:维护书籍和许可证激活统计
- 资产元数据:存储包含章节描述信息的音频资产元数据
- 音频资产:音频文件的存储
由于实际的服务是部署在AWS上的微服务,本文则简化并模拟了这些服务:
-
首先,资产元数据和音频资产服务是 AWS S3 存储桶(云存储)。为了模拟这一点,我们创建了 HTTP 服务,如果可用则返回包含资产的 200 OK,或者如果资产不存在则返回 404 Not Found。
-
其次,所有权和激活服务是 AWS RDS 实例。为了模拟这一点,我们创建了实现 REST 模式的 HTTP 服务:如果用户不拥有这本书,则返回 403 Forbidden,如果这本书不存在,则返回 404 Not Found,否则返回 200 OK。
-
第三,Stats 服务是一个 AWS DynamoDB 实例。为了模拟这一点,我们创建了一个返回 200 OK 的 HTTP 服务
Expedia
包含三个微服务:
- 按相关性顺序返回评论
- 按时间顺序返回评论
- API 网关:根据可用性从 Review ML 或 Review Time 向用户返回评论
Mailchimp
包含3个微服务:
- Requestmapper:将电子邮件活动中的高亮URL映射到实际资源URL
- DB Primary:他们数据库的主要副本
- DB Secondary:他们数据库的次要副本
- App Server:向Requestmapper服务请求解析URL,然后对数据库执行read-then-write请求,当主副本不可用时回退到二级数据库副本
- 负载均衡器:负载均衡请求
与 Mailchimp 的实际部署相比,我们表示为服务的一些组件实际上是非 HTTP 服务。我们在这里列举了这些差异和调整。首先,DB Primary 和 Secondary 服务是 MySQL 实例。为了模拟这一点,我们创建了一个 HTTP 服务,该服务在成功读取或写入时返回 200 OK,如果数据库为只读则返回 403 Forbidden。其次,Load Balancer 服务是一个 HAProxy 实例。为了模拟这一点,我们创建了一个 HTTP 代理。
Mailchimp 示例的错误包含两个:
- MySQL 实例只读。当 MySQL 实例为只读时,数据库会返回一个错误,该错误在代码的某个区域未处理。由于 Mailchimp 使用 PHP,这个错误被直接呈现到页面的输出中,我们通过将 403 Forbidden 响应转换为直接插入页面的输出来模拟这一点。
- Requestmapper 不可用。当 Requestmapper 服务不可用时,App Server 无法正确处理错误,向负载均衡器返回 500 Internal Server Error。但是,负载均衡器仅配置为通过返回格式化的错误页面来处理 503 Service Unavailable 错误。这是丢失或不正确的故障处理示例。
Netflix
包含10个微服务,与Audible示例类似,我们使用服务模拟 Netflix 移动应用程序,这里称为客户端:
- 客户端:模拟移动客户端
- API 网关:组装用户主页
- 用户档案:返回档案信息
- 书签:返回上次查看的位置
- 我的列表:返回用户列表中的电影列表
- 用户推荐:返回用户推荐的电影
- 评分:返回用户的评分
- 遥测:记录遥测信息
- 趋势:返回热门电影
- 全局推荐:返回推荐的电影
Netflix示例的bug包含三个,可以使用环境变量激活:
- 错误配置的超时。用户配置文件服务以 10 秒的超时时间调用遥测服务;但是,API 网关会以 1 秒的超时时间调用用户配置文件服务
- 服务回退到同一服务器。如果我的列表服务不可用,系统将重试(我的理解是,一个服务有3个实例,其中一个实例不可用,本应该请求其他实例,结果再次请求了那个不可用的实例)
- 没有回退的关键服务。用户配置文件服务没有后备处理逻辑