来源:NSDI ‘22
摘要
背景
精确定预估任务运行时间为有效的任务调度提供遍历。现有的任务调度基于历史数据学习,使用任务历史信息预估新任务。但是,由于部署模式转向快速迭代,快速部署这种方式不再精确。
本文工作
- 探索了实时学习任务运行时属性,通过主动采样和调度每个job的部分task,并探究这种方式的可行性和限制。这种方法利用了相同的任务在运行时的相似性。
- 在Azure上使用了3个生产集群,有不同的特性和任务分配。实验表明本文方法更为精确。同时减少了任务完成时间,相对以前的方法提升了1.28x/1.56x/1.32x。
- 同时将基于采样的学习拓展到DAG任务的调度中,也取得了比先前基于历史信息更快的任务完成时间。
Introduction
问题背景
集群中大数据任务的调度问题。
先前工作
较多的基于历史信息的学习算法,基于此进行任务调度。
这样的方法基于几个设定的前提条件:
- 这些job是重复性的,它们会多次执行;
- 相似job运行时表现出的特性相同。
⭐但是,先前工作的假设前提是有问题的:
- 很多job不是重复性的;
- 重复性的job每次运行时表现出的特性可能不会相同;
- 历史作业运行时特征具有相当大的变化。
本文工作
一种方法来在线学习分布式作业的运行时属性,以促进集群作业调度。
Motivation
基于集群中分布式任务关键信息的检测。
- 一个job的空间维度,或者说它包含的许多task信息;
- job的task(在同一阶段)通常执行相同的代码,并处理大小相似的不同数据。
上述观测到的信息是如何使用的呢?
首先,某个job的task得到了首先调度,然后基于该task,为其他的task提供调度指导。将这种学习方法称为“SLearn”,即“learning in space”。
这种方式避免了先前工作——基于历史信息学习进行调度的局限性。
Challenges of SLearn
- 预测精确度受到不同task运行时属性的影响;
- 将job的剩余task延迟到采样任务完成后再调度可能会影响作业的完成时间。
Comprehensive Comparative Study
本文对基于历史的学习(LIT, learning in time)和基于采样的学习(LIS, learning in space)进行综合的分析,提出下述问题:
- Learning in space是否比Learning in time更加精确❓
- 如果时,那是否可以提高剩余task的表现,来弥补上述的问题(剩余task需要依赖首先受到调度的task的信息,对前序task采样后再进行调度,影响作业完成时间)❓
并进行回答
问题1:通过定量分析,基于三个生产集群的job追踪(两个Google Cluster Trace数据集和一个2Sigma数据集),进行了回答。
问题2:设计了一个通用的job调度器,基于job运行时预估,去优化性能表现。将不同的预测方案接入调度器,如LIT和LIS。
Contribution
- 基于三个生产集群追踪数据分析,通过历史表征数据来预测分布式job未来的特性,是不准确和不稳定的。
- 提出SLearn,使用job的空间维度进行采样,对线上job的运行时属性进行学习。
- 通过定量、跟踪和实验分析,证明了SLearn可以比基于历史的方案更准确地预测作业的运行时属性。对于2Sigma、Google 2011和Google 2019集群追踪的数据集,预测结果的中值误差均有显著的优化。
- 在Azure上150个节点的集群实验中发现,对作业任务进行抽样来学习作业运行时属性,虽然延迟了作业剩余任务的调度,但可以通过提高精度来弥补性能损失,减少平均job完成时间。
- 展示了基于采样的学习可以被拓展到DAG job的调度中,实验表明相对于基于历史的学习策略,基于采样的学习可以缩短作业完成时间。
Background and Related Word
本文的核心点在于预测,那么具体预测什么呢?下图是先前基于历史学习技术进行预测的所做的工作:
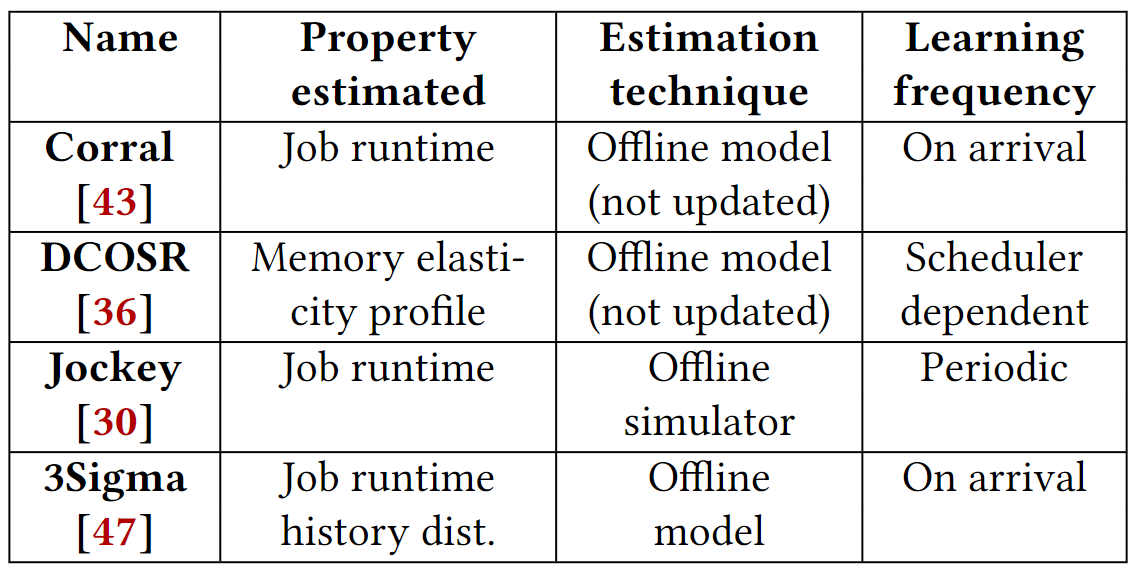
本文的将预测结果用于集群调度,使得调度结果满足SLOs要求。
SLEARN - Learning in Space
学习模块与调度是解耦的。
流程概述
- 在job下发后,预测器首先调度一个样本task,叫做pilot tasks,其产生的数据用于算法去学习job的运行时属性。
- 学习到的信息被注入集群job调度器,调度器执行多种策略以满足SLOs要求。
SLEARN细节
本文提出的方案可以有效的兼顾job的空间属性。
下图展示了LIT和LIS的不同:

简单总结
-
问题背景:特定的生产集群大数据处理任务的调度问题。
-
主要方法:针对基于历史信息预测的调度方法的不足,提出基于时空维度信息预测的调度方法。
-
评价指标:job的完成时间,少即使好。
-
实验:使用了三个开源生产集群中的Trace数据,在Azure上150个node进行实验。