来源: SoCC'21
作者: Alibaba Group
http://cloud.siat.ac.cn/pdca/socc2021-AlibabaTraceAnalysis.pdf
摘要
背景
理解微服务的特征,对利用微服务架构的特性很重要。然而,目前还没有对微服务及其相关系统在生产环境下的全面研究。
工作
我们对阿里巴巴集群中大规模部署微服务进行了详实的分析。研究重点是描述微服务的依赖关系及其运行时性能。
- 对微服务调用图进行了深入剖析,以量化它们与数据并行作业的传统DAG之间的区别
- 为合成更有代表性的微服务追踪轨迹,构建了数学模型去模拟调用图
结论
-
通过分析,发现调用图是重尾分布的
-
它们的拓扑结构类似于树
-
而且许多微服务都是热点(hot-spots)
-
发现三类有意义的调用依赖,可以用来优化微服务的设计。
-
大多数微服务对CPU受到的干扰比对内存受到的干扰更加敏感
Introduction
分析目标有20000个微服务,时间是7天,表征了它们的特性,包括动态的调用图,表征了微服务间调用依赖还有运行时性能分析。
微服务调用图与传统的数据并行处理任务DAG图明显不同
虽然可以看作有向图,但是有下面几个明显的不同:
- 调用图的大小遵循重尾分布,有10%的调用图包含超过40个微服务生命阶段,其他大多数只有几个阶段(因为由于服务运行时的动态性,不同时刻的调用图不同)
- 调用图的形状像树,大部分节点只有一条入边,与大数据任务的明显不同
- 存在微服务热点,5%的微服务被90%的微服务调用,而传统的DAG图中不会存在节点共享的情况
- 微服务在运行时有高度动态的调用关系,在极端的情况下,同一个在线服务有超过9类拓扑上不同的图
微服务的强依赖关系为优化微服务设计提供了方向
例如,优化两个强依赖关系的调用接口,提升上游、下游微服务间的通信效率,避免形成局部的性能瓶颈。
微服务对CPU扰动比对内存扰动更加敏感
CPU扰动会严重影响到响应时间。例如,CPU利用率在10%和30%时,响应时间相差20%。
同时,这表明需要对有效的任务调度策略有极大的需求,以平衡不同机器上CPU的利用率。
随机模型可以很好地模拟动态微服务调用图
现有的一些调用图不能展现服务运行时的调用状态,在整个生命周期中不会跟随请求的发生而动态改变。
为此,文章构建了一个随机模型,通过对微服务进行分类来生成调用图。
Contribution
- 首次对生产集群中的微服务进行详细的研究,包括微服务调用图的结构和依赖属性
- 对微服务运行时表现进行详细的表征,对微服务调度和资源管理给出深入的洞见
- 构建图模型来有效的生成大规模的微服务追踪结构,对在模拟图中表征结构性质进行了理论分析
Microservice Background And Alibaba Trace Overview
微服务架构
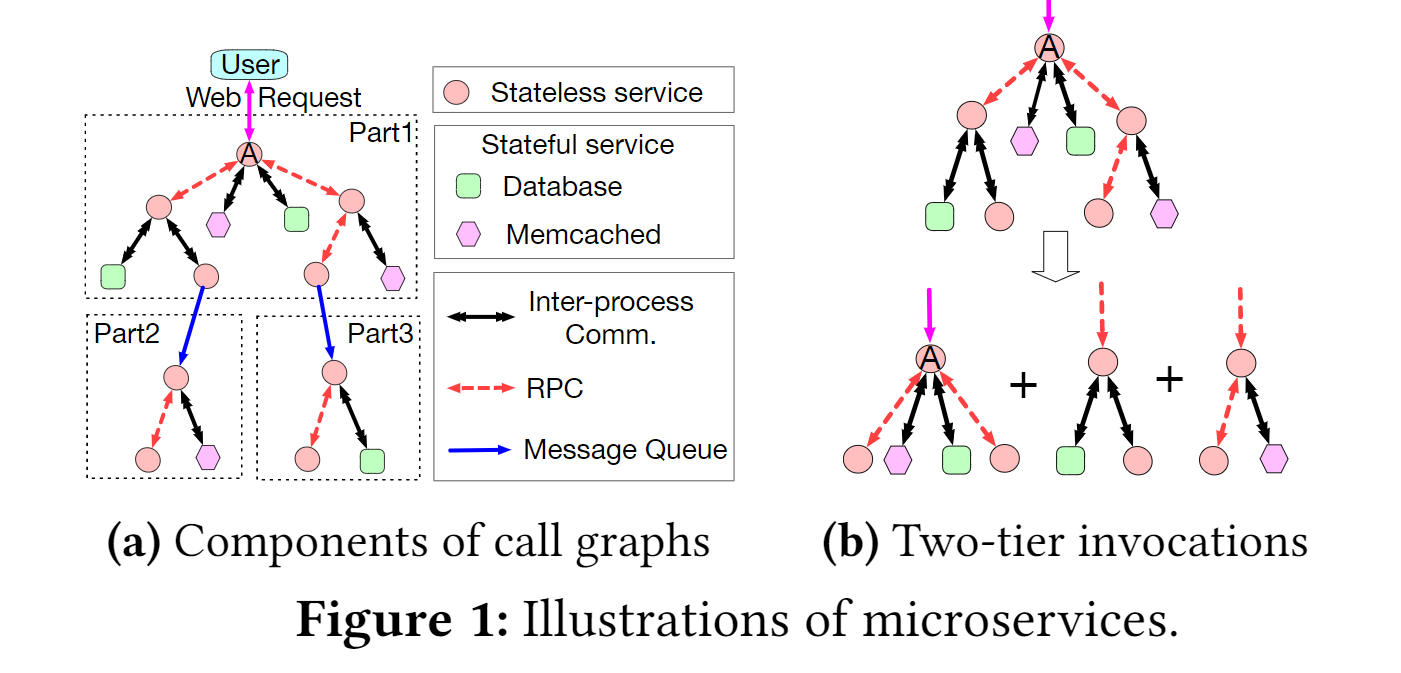
追踪概览
收集了超过100亿次调用的追踪。
物理运行环境
使用Kubernetes管理裸金属云环境,依赖硬件优化加强集群性能表现,并实现不同服务间的隔离性。如下图:
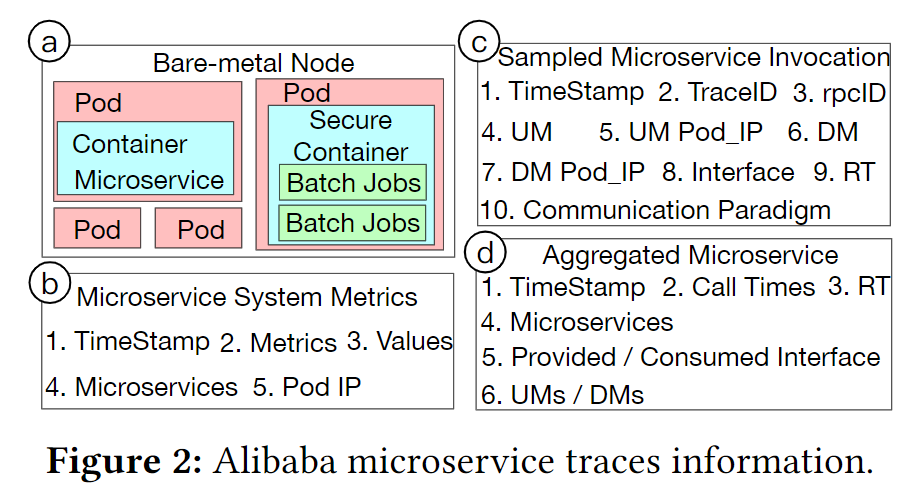
- 在线服务和离线服务会存在同一个裸金属节点上,以加强资源利用率
- 在线服务运行在容器中,直接被K8s所管理,而离线任务被分配定量的pods,交给调度器进行调度
- 批处理任务被放到安全容器中来保证安全性
- 有状态应用被部署在专门的节点上,不和其他无状态或是批处理应用共享机器
微服务系统测量
如Figure 2(b),微服务监控对每个容器的指标进行测量,隔段时间再求均值。测量的范围从硬件层面的缓存miss率,到操作系统层面的CPU利用率还有内存使用等,还有容器应用层面的例如JVM的堆使用和垃圾回收。
测量用Timestamp来作为时间序列的表征。
调用图中的微服务调用指标
如Figure 2(c):
- 微服务调用通过TraceID作为请求标识,代表一个调用图
- interface是上游服务和下游服务的调用接口
- 还记录了上下游服务Pod的IP
- 上下游调用的响应时间
- …
聚合调用
如Figure 2(d),微服务的调用情况也会被记录:调用时间戳、响应时间、微服务、调用和被调用的接口、上下游微服务。
解析调用图
微服务调用图的特性
**微服务调用图的数量呈现重尾分布。**大多数调用图只包含少数微服务,调用层级不超过3层。但有的调用图包含大量的微服务和很深的层次,如下图:
- 图中的微服务数量呈现Burr分布
- 超过10%的服务包含超过40个不同的微服务
- 超过40个微服务的大型应用中,大约有50%的微服务是缓存服务(因为系统越庞大,需要缓存来加快系统响应时间,使用缓存比数据库有更高的效率)
下图是调用图深度的分布:
- 平均深度为4.27层
- 深度在3层的服务居多
- 仍有超过4%的调用图超过10层
所带来的问题是,如何使用深度学习方法,为这些服务分配正确的容器数量,如[17, 40]。这些方法将不同层次的微服务进行编码,并将实时的资源分配作为神经网络的输入向量。但是这样很容易产生过拟合现象,调用图规模太大,而用于调整模型的负标签太少,如RT violation现象。
因此,急需找到合适的方法有效的为大规模微服务分配资源。
微服务调用图像一棵树,许多图包含一条较长的链。如下图:
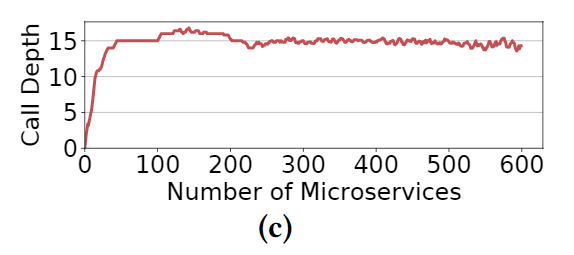
- 当微服务数量不断增加,调用深度逐渐稳定
- 如果一个微服务调用涉及到有状态服务,那么一般来说这条调用链不会再延长,终止于有状态服务
关于调用图节点的出边和入边分布如下图:
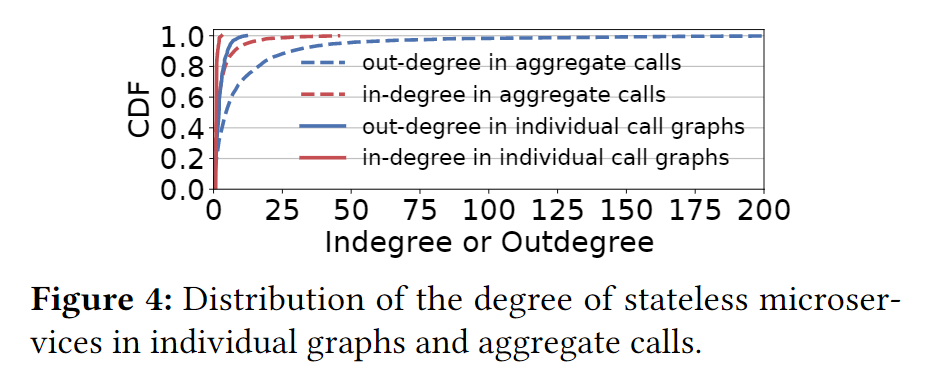
- 超过10%的有状态服务至少有5条出边
- 大多数微服务只有一条入边
一旦微服务层数大于2时,相关层包含的微服务一般只有一个,如下图:
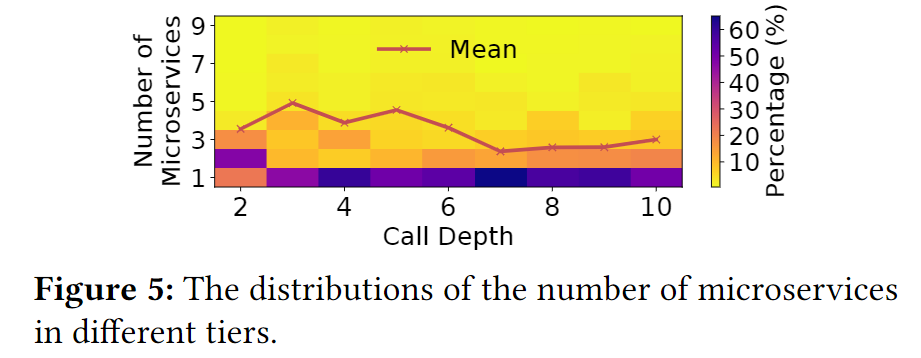
例如,当层数在10层时,有超过50%的情况是这层只有一个微服务。也就是上面提到的,为什么深度越深,就越是表现出链式结构。此外,这种情况也利于查找微服务调用中出现的瓶颈。
无状态服务容易成为hot-spots。如上面的Figure 4所示,超过5%的微服务在聚合调用后有超过16条入边,这些超级微服务承载力将近90%的调用,涉及到95%的调用。因此这种松耦合架构展现了严重的负载不平衡。这有利于资源扩展,因为系统管理员应该只关注单个微服务的扩展,并为这些超级微服务分配更多的容器。
**微服务调用图有很高的动态性。**即使是同一个在线应用,它们生成的调用拓扑图都有显著的差异。例如同一个付款请求,一个有优惠券的用户和一个会员用户或者一个普通用户,请求的调用的微服务都有显著的不同。如下图,所有在线服务都至少有两类图拓扑结构:

另外,还有超过10%的微服务呈现9中调用模式。**这进一步给基于图的微服务预测任务带来了巨大的挑战。**现有的基于CNN的微服务资源管理方法不能描述这些动态特性,也不适用于实际的工业应用。
图学习算法
该算法的目的在于:将调用图中的微服务进行分类。关键点是将每个微服务转换为一个向量。如InfoGraph算法,这是无监督学习,它将节点信息(如某种微服务),还有边信息(如微服务的调用关系),做成邻接矩阵作为深度神经网络的输入。
通过综合训练集的信息,InfoGraph可以为每个图生成一个嵌入向量。
文章分别训练每个在线服务,并在嵌入的20维向量上使用K-means聚类,将该服务生成的所有调用图分组为多个类。聚类的数量在[2,10]中,并用来生成平均轮廓系数。
在聚类后,使用通用方法Graph Kernel,用来生成两个图间的相似度。
对图进行聚类和相似判断的算法如下:
详细分析
无状态微服务的调用模式在不同的层上有很大的不同
- 通常无状态服务没有下游微服务,调用图一般不会在无状态服务处继续扩展
消息队列对减少深层次的调用图的端到端时延很有帮助
- 对于依赖缓存的服务,当缓存未命中时,会花费大量时间调用数据库服务
- 当深度增加时,无状态微服务和数据库(即S2D)之间的通信百分比呈亚线性增长
下图中:
- 图a展示不同类型的无状态服务对调用层数的影响
- 图b展示了随着深度增加,服务间通信类型,请求类型的占比
无状态服务间依赖
上文中提到,无状态服务过多依赖其他的存储服务,一些时候不可避免的带来服务资源占用。通过研究无状态服务间依赖以避免通信过载和死锁的发生。
循环依赖关系
下图为循环依赖关系的简单实例:
这种依赖分为:强依赖关系和弱依赖关系。强循环依赖如果设计不合理,会导致死锁。
- 强循环依赖关系:上游的输入接口与下游的应答接口相同,直接的就是I1=I3
- 弱循环依赖关系:I1 != I3
循环依赖关系在调用图同不可忽视
下图展示循环依赖的占比以及这些依赖使用的通信方式:
- 大多数通信模式使用RPC进行
- 在所有的循环依赖中,2.7%是强依赖关系
耦合依赖:高频率的调用次数和长调用时间
对于调用率和调用次数的计算如下:
Count(X):上游Y调用下游M的次数(相邻两层中,X可能会被Y多次调用)
Sum:表示所有调用图中由Y触发的两层调用的数量
N:为两层调用中X被调用的数量
如果Call Probability和Call Time的值超过2和0.9,就说这两个服务是耦合依赖的。
对于有强耦合依赖的服务,可以将它们的接口做到一起以优化,减轻网络拥塞。
并行依赖
并行依赖可以减轻上游服务的响应时间。但是在这种情况下建议将服务做进一个微服务中。
微服务运行时表现
理解微服务运行时的情况有利于保证服务质量。在本节中,文章研究图拓扑和资源干扰以及微服务调用率(MCR)对响应时间的影响。
微服务调用率
MCR记录了每个容器每分钟接收调用的次数。如果MCR过大,可能意味着资源紧张。
使用Spearman相关系数来评估MCR序列和微服务容器运行时的序列。如下图:
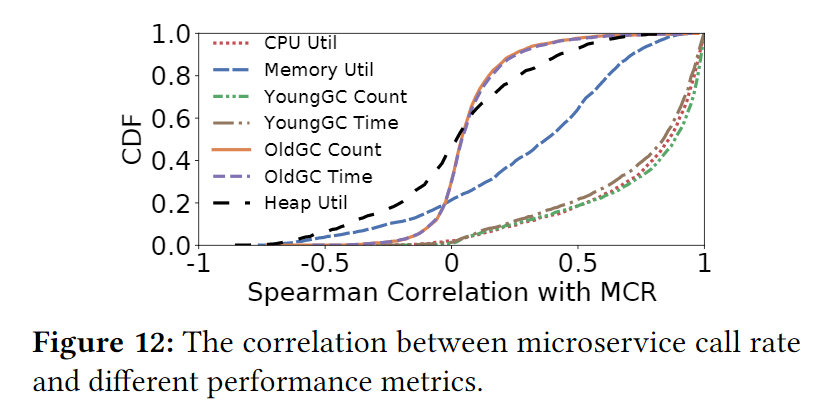
上图展示了MCR和多种不同的系统层面和应用层面的资源调用的累积分布。
- 微服务调用率与CPU利用率和Young GC高度相关,但与内存利用率无关
- 说明CPU利用率和Young GCs最能反应资源紧张程度
微服务响应时间表现
本部分研究调用图的复杂性、资源竞争和MCR以及其他因素对微服务响应时间表现的影响。
端到端时延在拓扑结构类似的调用图中较为稳定,而在拓扑结构不同的调用图中显得很大不同。
通过上面的图聚类算法将调用图进行分类,对每类图中的响应时间进行计算。这进一步说明图拓扑结构对端到端RT有很大的影响。此外,文章设计的图学习算法可以用于预测RT性能。
端到端性能会由于CPU的高占用而下降。
**在微服务调用率变化时,时延并没有太大波动,**这是由于在集群中及时处理了调用请求避免消息堆积。
用概率模型生成微服务图
涉及到的算法暂时没看太懂…
相关工作
- Microservice benchmarks
- Serverless benchmarks
- Cloud workloads
- Cloud trace analysis
- Performance characterization of online services