来源:NSDI'22
推荐阅读!
摘要
背景
越来越多的ML模型运行在公有云环境下。为这些模型服务的框架能够以最小的延迟提供高度准确的预测,并降低部署成本,这一点至关重要。
关键点
模型集成可以通过智能地将不同模型并行组合来解决精度差距问题。然而,在运行时动态地选择合适的模型,以以最小的部署成本、低延迟来满足预期的准确性。
本文工作
提出Cocktail,基于模型集成的成本效益模型服务框架。包含两个关键的组件:
- 一个动态模型选择框架,在满足精度和延迟要求的同时,减少了集成中的模型数量。
- 一个采用分布式主动自动伸缩策略的自适应资源管理(RM,Resource Management)框架,有效地为模型分配资源。RM框架利用瞬态虚拟机实例来降低公共云中的部署成本
同时在AWS EC2实例中实现了一个原型系统,演示了使用各种工作负载的详尽评估。结果显示Cocktail减少了部署花费1.45x,与最先进的模型服务框架相比,减少了2x延迟,并满足高达96%的请求的目标精度。
Introduction
背景及问题引出
背景案例:Facebook为用户交互应用程序提供了数万亿的推理请求,如对新提要进行排名,对照片进行分类等。这些应用程序必须在亚毫秒延迟[27、34、35、39、44、83]提供准确的预测,因为它们严重影响用户体验。
随着许多应用使用ML技术增强其用户体验,这种趋势正在扩大。
通常这种模型服务运行在云平台上,如一些model-serving框架[6, 28, 60]。
挑战
由于训练数据以及计算和内存资源紧张[59,65,84]造成的高方差一直是设计高精度和低延迟模型的主要障碍
不同于单模型推理任务,ensemble learning集成学习可以进一步提高服务精确度。(如,多模型的图片分类任务会提高最终的精确度)
然而,对于集成,由于每个请求都需要运行大量的模型[27,56]而导致的非常高的资源占用,加剧了公共云的部署成本,并导致延迟的高度变化。
因此,本文解决的主要问题为:
⭐集成单一的模型推理服务;
⭐同时提高模型服务的准确度;
⭐并最小化部署成本。
现有技术的不足
对最先进的集成模型服务框架进行分析,存在如下不足:
- 在像Clipper[27]这样的框架中使用的集成模型选择策略是静态的,因为它们集成了所有可用的模型,并只专注于最小化准确性损失。这将导致更高的延迟,并进一步扩大资源使用,从而加重部署成本。
- 现有的集合权重估计[87]计算复杂度高,在实践中仅限于一小部分现成模型。这导致精度损失严重。此外,采用线性集成技术(如模型平均)计算量大[80],且对大量可用模型不可伸缩,缺少弹性。
- 现有的集成系统不关注公共云基础设施中的模型部署,没有注意到部署成本和延迟。
- 对单一模型的资源管理模采用的策略不能直接扩展到集成系统中。
因此,重复之前亟待解决的问题:
⚠️如何解决集成框架的成本、精度和延迟等复杂优化问题?
本文工作
Cocktail,首个成本友好、集成多模型的ML服务框架,针对于分类推理任务,有很好的精确度和低延迟表现。
它使用下面三方面解决框架优化问题:
- 提出了一种动态模型选择策略,在满足延迟和精度要求的同时,显著减少了集成中使用的模型数量;
- 利用分布式自动伸缩策略来减少托管集成模型的延迟可变性和资源消耗;
- 利用transient VMs技术减少了推理服务部署成本(比传统的虚拟机减少79%-90%的成本)。
Contributions
- 通过描述集成模型的精度与延迟,我们发现在给定的延迟下谨慎地选择可用模型的子集可以达到目标精度。在Cocktail中利用这一点,设计了一种新颖的动态模型选择策略,在保证准确性的同时大大减少了模型的数量。
- 关注基于分类的推理,最小化来自多个模型的预测偏差。Cocktail采用了一个pre-class加权多数投票政策,这使得它具有可扩展性,与传统加权平均相比,有效地打破了不同模型之间的联系,从而最大限度地提高了准确性。
- 集成模型资源需求的变动会导致资源的过度供应,为了最小化资源,我们构建了一个分布式的加权自动伸缩策略,该策略利用重要抽样技术主动地为每个模型分配资源。Cocktail使用transient VMs降低模型在云平台上部署的成本。
- 使用AWS EC2的CPU和GPU实例,实现了原型系统Cocktail并对不同的请求进行了评估。与最先进的模型服务系统相比,部署成本降低1.4x,精确度提升至96%,延迟减少2x。
- 同时表明,集成模型的Cocktail,Cocktail可以通过将准确度损失限制在0.6%以内来适应实例故障,对故障容忍性有较大提升。
Background and Motivation
本章结构如下:
- 分析现有公有云中的集成模型服务;
- 指出这些服务存在的问题;
- 表明Cocktail基于以上问题需要做的改进。
Model Serving in Public Cloud
现有公有云模型服务架构如下:
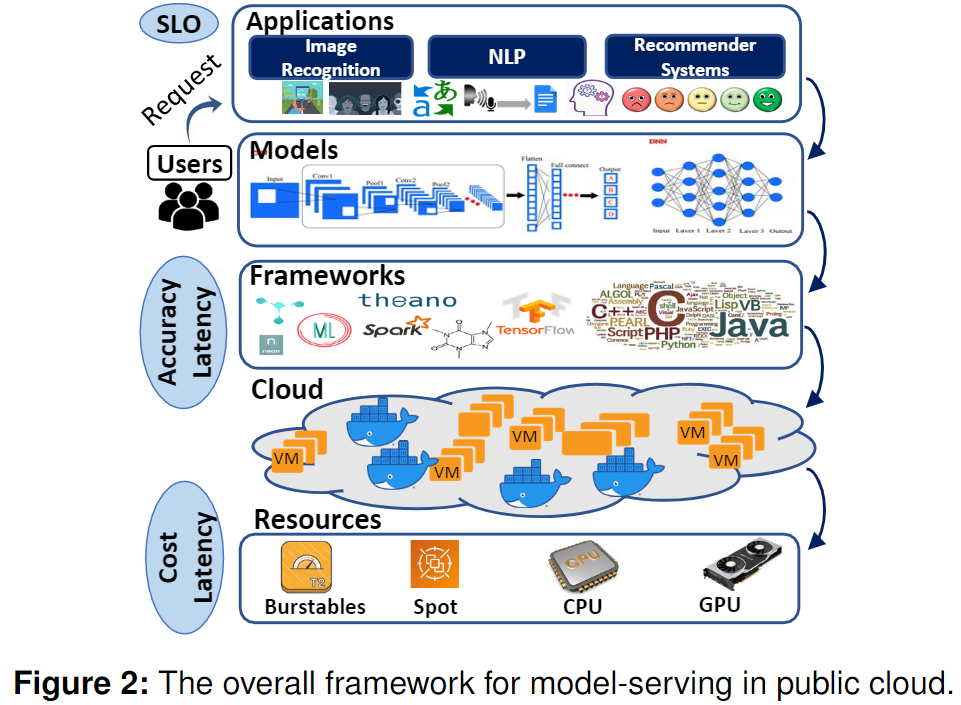
Application层
关注SLO,本文指End2End的响应时间。如Ads服务在100ms、推荐服务可以容忍1000ms。
Model 层和 Framework 层
部署的如TensorFlow、PyTorch框架。以及提供的不同模型(这里以分类模型为例):
根据应用程序类型,最大的模型集成尺寸可以从数十到数百个模型不等。
Cloud 层
以VMs或者Container提供资源隔离和运行环境,基于异构的CPU、GPU实例。
其中,瞬态实例[69]与传统的VM类似,但可以由云提供商在任何时间通过中断通知撤销。这些资源的供应延迟、实例持久性和模型打包花费直接影响到托管模型服务的延迟和成本。
本文从模型选择的角度关注于提高准确性和延迟,并从成本的角度考虑实例类型。
Related Work
下图为本文工作和先前相关工作的对比:
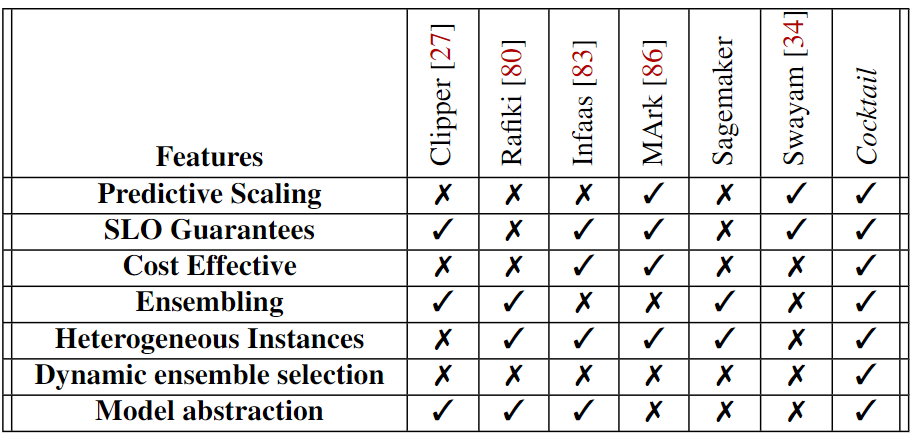
1️⃣现有的集成模型案例:
- Azure ML-studio:最初集成了5个模型,现在逐渐扩展到200个模型。
- AWS Autogluon:集成了6-12个模型。
用户可以手动选择模型数量规模。
与它们不同的是,Cocktail的模型选择策略试图在给定延迟的情况下选择合适的集合大小,同时最大化准确性。
2️⃣云上模型服务:
InFaas、Clipper 、FrugalML、MArk 、Rafiki、 TF-Serving、 SageMaker、AzureML 、Deep-Studio等。
3️⃣公有云自动缩放:
现有相关的资源配置策略能分为两类:
- 多路复用不同的实例类型;
- 基于预测策略的主动资源发放。
Cocktail使用了类似的负荷预测模型,并在模型集合方面以分布式的方式使用自动缩放虚拟机。
Cocktail的自动缩放策略与Swayam[34]的分布式自动缩放策略有相似之处;然而,我们进一步引入了新颖的重要采样技术,以减少未充分利用的模型的过度供应
引出Cocktail
首先回答两个问题:
1️⃣如何减少资源占用❓
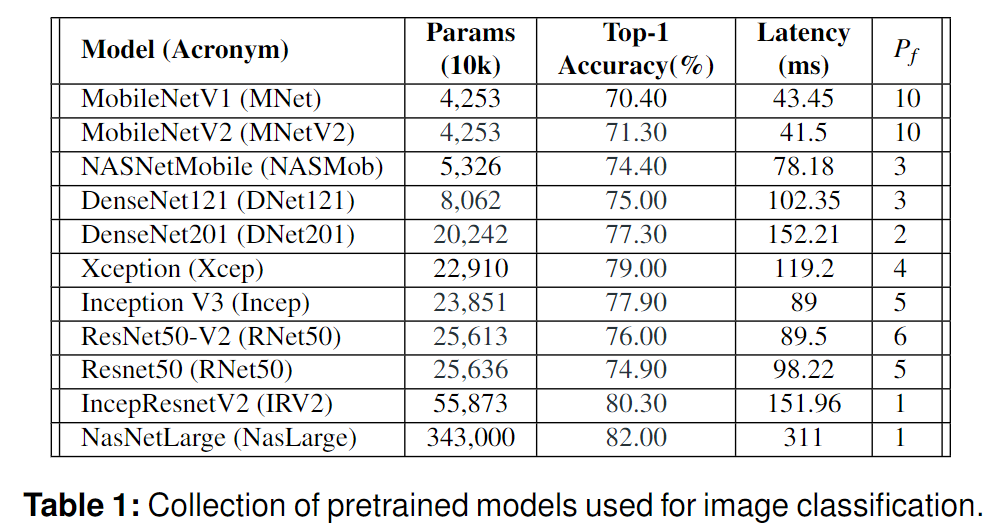
通过最小化模型集成数量,减少资源使用。文章通过实验,选取精度前50%的模型进行集成。
完全集成的模型选择是一种过度的行为,而静态集成则会导致精度的损失。这就需要一个动态的模型选择策略,该策略可以根据模型选择策略的准确性和可伸缩性准确地确定所需的模型数量。
2️⃣如何减少部署成本❓
大多数云提供商提供瞬态虚拟机,如Amazon Spot实例[69]、谷歌preemptible VMs[9]和Azure Low-priority VMs[7],可以降低高达10倍的云计算成本。文章**利用这些瞬态VMs(如spot实例)**来大幅降低部署集成模型框架的成本。
Cocktail整体设计
Cocktail架构如下:
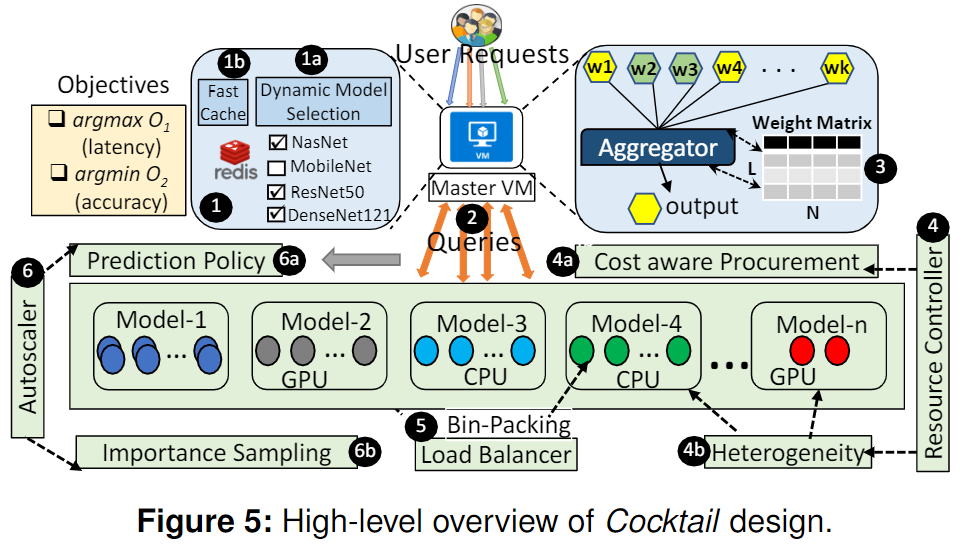
- Master VM:运行了模型选择算法;1a)来决定将哪些模型集成;1b)被选中的模型加载到缓存中,在相同请求到来时加快响应速度。
- Queries:各个请求分派到不同的实例池。
- Aggregator:用来处理集成模型的返回结果,使用加权多数投票聚合器返回正确的预测。
为了有效地解决资源管理和可伸缩性的挑战,Cocktail应用多种策略。它维护专用的实例池服务于各个模型,这简化了每个模型的管理和负载平衡开销。
- Resource Controller:主要管理实例的增减,通过 4a)4b)基于CPU和GPU的开销进行实例数量的管理。
- Load Balancer:将Queries分配给适当的实例,并确保所有获取的实例都被打包到VM中。
- Autoscaler:利用 6a)预测策略为实例池中的实例预测请求负载,确保资源不会被过度配置;同时使用 6b)重要性抽样算法,通过计算每个模型池在给定时间间隔内所服务的请求的百分比来估计每个模型的重要性。
动态模型选择策略
目标函数
本文使用一个基于窗口的动态模型选择策略,使用下面描述的两个目标函数:

目标时减小延迟和花费并最大化准确率。
- $\mu_{AL}$: latency-accuracy metric
- $\mu_c$:cost metric
- $Acc_{target}$:目标准确度
- $Lat_{target}$:目标延迟
- $N$:参与集成的模型数量
- $inst_cost$: VM实例的花费
- $m$:指每个模型
- $P_{f_m}$:在单个实例中可以并发执行而不违反延迟指标的推理数量,越大越好
- $k$:常量,取决于VM的性能配置
第一个目标函数$O_1$就是满足$Acc_{target}$和$Lat_{target}$时最大化$\mu_{AL}$。
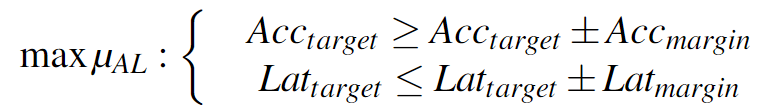
为此,初始模型列表在满足$Lat_{target}$的模型中选择,并尝试集成使其满足$Acc_{target}$。
Cocktail会将每个模型的准确性作为正确概率,然后迭代地构建一个模型列表,其中它们执行分类的联合概率在准确性目标内。
- $Acc_{margin}$:为0.2%
- $Lat_{margin}$:为5ms
第二个目标函数$O_2$是最小化$\mu_c$。
该目标调整模型清单的大小,并进一步调整资源采购。因此最大化$P_{f_m}$,最小化$k$。
对于$N$个模型,每个模型都有一个最小精度,因此选取最小精度前50%的模型,数量为${N\over2} + 1$。来保证集成模型达到预期精度。结果正确率如下:
模型选择和加权多数投票策略
为最小化$\mu_c$,设计了一个模型数量缩减策略,只要有超过${N\over2}+1$的模型选择同一种结果,如下图:

资源管理
资源控制器 Resource Controller
- Resource Types: CPU和GPU实例。GPU实例在打包大量请求执行时是划算的。文章提出自适应打包策略,考虑每个实例的$P_f$ 以及在时间$T$到来的请求数量。只有工作负载匹配$P_f$时,才会将负载分发到对应实例。
- Cost-aware Procurement: 在一个完全封装的实例中执行请求的成本决定了每个实例的开销。在扩展实例之前,需要估计将它们与现有实例一起运行的成本。在时间$T$时,基于预测负载$L_p$和运行实例$R_N$,使用cost-aware greedy策略来决定要增加的实例数量。
- Load Balancer: 在每个模型池中维护一个请求队列,为增加实例池中实例的利用率,负载均衡器将来自队列的每个请求提交到剩余空闲槽位(free slots)。文章使用预期超时10分钟的间隔,来回收实例池中没有被使用的实例。贪婪地分配请求可以使负载较轻的实例更早地伸缩。
自动伸缩器 Autoscaler
我们需要自动伸缩实例数量,来弹性的满足到来的请求负载。Cocktail能准确预测给定时间间隔内的预期负荷。如果需要,Cocktail增加实例到实例池。每隔10秒对SLO违例进行采样,并根据所有实例的资源利用率聚合为每个池生成额外的实例。捕获由于错误预测而导致的SLO违反。
-
预测策略:本文设计了DeepARestimator模型。每个模型有1分钟的定期调度间隔$T_s$,在时间$T+T_p$使用预测负责$L_p$,与当前负载$C_p$进行比较,来决定实例数量$I_n$。其中,$T_p$为新实例的平均启动时间。$T_s$设定为1分钟是考虑到AWS EC2 VMs实例的启动时间。为计算$L_p$,对过去S秒内大小为$W$的相邻窗口的到达率进行采样。使用所有窗口的全局到达率,来预测时间$T$在加减$T_p$时间单元中的$L_p$。$T_p$设置为10分钟,使它有足够的时间来捕捉未来长期的变化。所有这些参数都可以根据系统的需要进行调整。
-
Importance Sampling: 在自动伸缩中一个重要的问题是模型选择策略为给定的请求约束动态地确定集合中的模型。**基于预测的负载,为每个模型平等地自动伸缩实例,将固有地导致为未充分使用的模型提供过多的实例。**为了解决这个问题,设计了一个加权自动缩放策略,它基于权重智能地为每个池自动缩放实例。算法如下图:
自动缩放策略如下:

权重取决于模型被请求(get_popularity)的频率。权重与每个模型池的伸缩实例(launch_workers)的预测负载相乘。这种方法称为Importance Sampling,因为模型池的大小与它们的受欢迎程度成正比。
本论文实验做得非常充分!可以作为范本。