为体验Kubernetes以及Cilium组合在一起产生的新特性,我计划将Kubernetes升级到1.24+,并使用最新的稳定版cilium1.12来作集群网络。
我所看重的最大改变:
- kubernetes1.24+正式移除dockershim,关于“kubernetes弃用Docker”这一话题也算是尘埃落定,kubernetes正式拥抱纯净的CRI。
- cilium1.12后正式支持kubernetes1.24.0,并且其重大的新特性cilium service mesh引起了我的兴趣,“multi control plan”、“sidercar/sidercar-free”等亮点让我很想尝试,是不是基于eBPF的service mesh在性能开销、指标粒度上能够给云上可观测性带来更好的体验。
所以,第一个问题来了,移除dockershim后,我们怎样继续使用docker engine作为底层的容器管理以及运行时管理者呢?
Dockershim和容器运行时
我们知道,提供服务的终点是Pod中运行的容器,kubernetes本身并不提供这种能力,而是依赖CRI去接入其他容器运行时,实现这样的能力的。我们最直接的体会就是kubernetes可以按照声明文件自动拉取、运行容器,其实这都是容器运行时的工作。例如docker,它就有这样的能力,并且在k8s发展初期,Docker甚至比k8s更有知名度,同时Docker比k8s CRI这样概念要早,docker engine也就没有实现CRI接口这一说,所以k8s使用dockershim作为支撑docker这一容器运行时的过渡。因此在k8s早期版本,就针对docker这个容器运行时做了适配。
每个节点上的kubelet在dockershim的能力下,可以与节点上的docker engine进行交互,去使用docker的能力。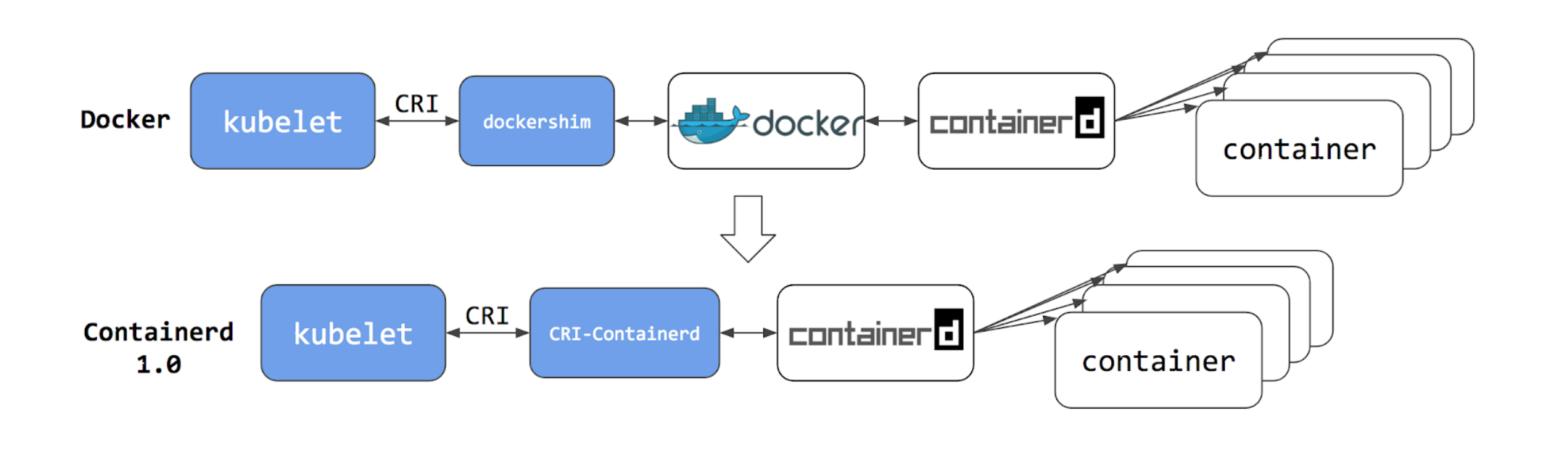
从上图中可以看出,dockershim的作用与一个CRI实现是一样的。尽管目前docker底层也是使用了containerd,但是我们还需要多一个中间环节,用docker调用containerd。
而k8s中CRI之一containerd则为k8s提供了直接调用containerd的能力。
目前主要的CRI实现有:
- containerd
- cri-o
- cri-dockerd
正因如此,k8s不必局限于docker这一种运行时,CRI的能力可以让k8s使用特性不同的容器运行时。
弃用dockershim后,Docker还有用吗?
当然。
在我的印象里,docker仍然是目前使用最多的容器打包构建、镜像管理和运行工具。docker hub有丰富镜像资源、有很多开发者在使用docker去构建自己应用镜像。使用docker build打包的镜像依然符合CRI的标准(因为已经容器运行时以及有标准化组织OCI为其制定规范了)。
只不过,原来为docker engine做适配工作现在已经不属于k8s社区的管辖范围,需要其他社区自己去按照CRI的标准,为docker engine编写接入k8s的“转接头”。因此,就有了cri-dockerd。
如果我们想继续使用在k8s中使用docker,就必须使用cri-dockerd作为适配器,它让我们可以通过CRI来使用docker engine。
在新版本集群中使用cri-dockerd
之前的博客中我们分享到,搭建集群只需要节点上有docker engine就可以,然后按照kubeadm,kubelet,kubectl就可以了,不会去刻意、显式的配置容器运行时。那是因为k8s内置的dockershim自动帮我们完成了这个工作。
在1.24.0之后,我们在创建集群之前,也要像安装CNI那样先配置我们的容器运行时,才可以正常初始化k8s集群。
安装并配置cri-dockerd
⚠️这需要节点上有正常运行的docker engine。同时要在所有节点上安装cri-dockerd。
我们这里使用Ubuntu22.04作为环境,直接在release下载构建好的对应Ubuntu版本的.deb安装文件。
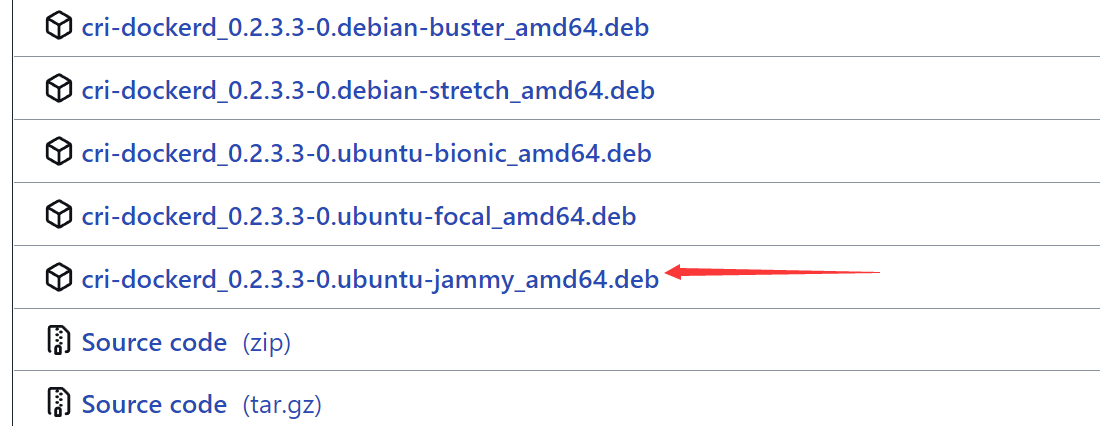
然后,进行安装:
> dpkg -i cri-dockerd_0.2.3.3-0.ubuntu-jammy_amd64.deb
Selecting previously unselected package cri-dockerd.
(Reading database ... 212454 files and directories currently installed.)
Preparing to unpack cri-dockerd_0.2.3.3-0.ubuntu-jammy_amd64.deb ...
Unpacking cri-dockerd (0.2.3~3-0~ubuntu-jammy) ...
Setting up cri-dockerd (0.2.3~3-0~ubuntu-jammy) ...
Created symlink /etc/systemd/system/multi-user.target.wants/cri-docker.service → /lib/systemd/system/cri-docker.service.
Created symlink /etc/systemd/system/sockets.target.wants/cri-docker.socket → /lib/systemd/system/cri-docker.socket.
安装log里有两个很重要的信息点:
Created symlink /etc/systemd/system/multi-user.target.wants/cri-docker.service → /lib/systemd/system/cri-docker.service.
Created symlink /etc/systemd/system/sockets.target.wants/cri-docker.socket → /lib/systemd/system/cri-docker.socket.
sysmlink是Linux中的一种文件类型,称为“符号链接”、“软链接”,指向计算机上另一个文件或者文件夹。类似于Windows中的快捷方式。这种链接文件记录了被链接文件的路径,更方便的访问某些文件。
在安装cri-dockerd时,为cri-docker.service,和cri-docker.socket创建了软链接。
安装后,我们执行cri-dockerd -h 了解一下基本信息:
> cri-dockerd -h
CRI that connects to the Docker Daemon
Usage:
cri-dockerd [flags]
Flags:
--buildinfo Prints the build information about cri-dockerd
--cni-bin-dir string <Warning: Alpha feature> A comma-separated list of full paths of directories in which to search for CNI plugin binaries. (default "/opt/cni/bin")
--cni-cache-dir string <Warning: Alpha feature> The full path of the directory in which CNI should store cache files. (default "/var/lib/cni/cache")
--cni-conf-dir string <Warning: Alpha feature> The full path of the directory in which to search for CNI config files (default "/etc/cni/net.d")
--container-runtime-endpoint string The endpoint of backend runtime service. Currently unix socket and tcp endpoints are supported on Linux, while npipe and tcp endpoints are supported on windows. Examples:'unix:///var/run/cri-dockerd.sock', 'npipe:////./pipe/cri-dockerd' (default "unix:///var/run/cri-dockerd.sock")
--cri-dockerd-root-directory string Path to the cri-dockerd root directory. (default "/var/lib/cri-dockerd")
--docker-endpoint string Use this for the docker endpoint to communicate with. (default "unix:///var/run/docker.sock")
--hairpin-mode HairpinMode <Warning: Alpha feature> The mode of hairpin to use. (default none)
-h, --help Help for cri-dockerd
--image-pull-progress-deadline duration If no pulling progress is made before this deadline, the image pulling will be cancelled. (default 1m0s)
--ipv6-dual-stack Enable IPv6 dual stack support
--log-level string The log level for cri-docker (default "info")
--network-plugin string <Warning: Alpha feature> The name of the network plugin to be invoked for various events in kubelet/pod lifecycle.
--network-plugin-mtu int32 <Warning: Alpha feature> The MTU to be passed to the network plugin, to override the default. Set to 0 to use the default 1460 MTU.
--pod-cidr string The CIDR to use for pod IP addresses, only used in standalone mode. In cluster mode, this is obtained from the master. For IPv6, the maximum number of IP's allocated is 65536
--pod-infra-container-image string The image whose network/ipc namespaces containers in each pod will use (default "k8s.gcr.io/pause:3.6")
--runtime-cgroups string Optional absolute name of cgroups to create and run the runtime in.
--version Prints the version of cri-dockerd
从“CRI that connects to the Docker Daemon”中看到,cri-dockerd的作用是连接节点上的docker daemon的,然后k8s再连接cri-dockerd,就能使用docker作为容器运行时了。
--cni-bin-dir string--cni-cache-dir string--cni-conf-dir string
上面三个参数是关于容器网络的,暂时在alpha阶段。
--container-runtime-endpoint
这个参数需要我们注意,它指定了k8s需要连接CRI端点,默认是unix:///var/run/cri-dockerd.sock,在后面配置kubeadm config时需要用到。
--docker-endpoint string
这个参数就是cri-dockerd要去连接的docker daemon的端点,来使用docker的能力。
--pod-cidr string
该参数只有在单节点部署时才会用到,在集群环境下cri-dockerd通过获取master node的信息知晓pod的cidr划分。
--pod-infra-container-image
该参数可以用来设置Pod中的pause容器的镜像版本,默认使用k8s.gcr.io/pause:3.6这个镜像。但是在k8s1.24中,应该使用3.7版本,并且要换成aliyun镜像,在后面需要设置。
修改kubeadm config文件
我先导出kubeadm默认的启动配置文件。
kubeadm config print init-defaults > kubeadm1.24.conf
然后做一些修改,我的修改如下:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.153.21
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/cri-dockerd.sock
imagePullPolicy: IfNotPresent
name: nm
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.24.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.5.0.0/16
scheduler: {}
需要注意的几个点有:
advertiseAddress: 192.168.153.21:设置控制平面API Server的地址和端口。criSocket: unix:///var/run/cri-dockerd.sock:这需要特别注意,criSocket就是上面我们说的cri-dockerd中的--container-runtime-endpoint参数,如果使用了别的容器运行时这里也要相应修改。name: nm:本机的hostname。imageRepository: registry.aliyuncs.com/google_containers:国内用aliyun的镜像。podSubnet: 10.5.0.0/16:Pod cidr信息。
启动集群(启动失败)
然后我们尝试启动集群:
# kubeadm init --config ../create-cluster/kubeadm1.24.conf
[init] Using Kubernetes version: v1.24.0
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: blkio
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2022-07-31T15:41:42+08:00" level=debug msg="get runtime connection"
time="2022-07-31T15:41:42+08:00" level=fatal msg="unable to determine runtime API version: rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial unix /var/run/cri-dockerd.sock: connect: connection refused\""
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
发现报错了level=fatal msg="unable to determine runtime API version: rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial unix /var/run/cri-dockerd.sock: connect: connection refused\"。我们的socket没有连上。
原因就是,我们安装了cri-dockerd后,它并不会像systemctl所管理的service,或者守护进程那样自动驻留在本机上。我们必须手动的启动cri-dockerd。
所以,需要手动运行cri-dockerd,并且添加--pod-infra-container-image参数。(使用kubeadm config images list --config kubeadm1.24.conf可以知道需要的镜像版本)
> cri-dockerd --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
INFO[0000] Connecting to docker on the Endpoint unix:///var/run/docker.sock
INFO[0000] Start docker client with request timeout 0s
INFO[0000] Hairpin mode is set to none
INFO[0000] Docker cri networking managed by network plugin kubernetes.io/no-op
INFO[0000] Docker Info: &{ID:HEPZ:PXCZ:XHZR:SKBX:TJL5:EG5L:U6P3:PI5A:PVZZ:ASKB:QJUC:QEDR Containers:2 ContainersRunning:1 ContainersPaused:0 ContainersStopped:1 Images:13 Driver:overlay2 DriverStatus:[[Backing Filesystem extfs] [Supports d_type true] [Native Overlay Diff true] [userxattr false]] SystemStatus:[] Plugins:{Volume:[local] Network:[bridge host ipvlan macvlan null overlay] Authorization:[] Log:[awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog]} MemoryLimit:true SwapLimit:true KernelMemory:false KernelMemoryTCP:false CPUCfsPeriod:true CPUCfsQuota:true CPUShares:true CPUSet:true PidsLimit:true IPv4Forwarding:true BridgeNfIptables:true BridgeNfIP6tables:true Debug:false NFd:31 OomKillDisable:false NGoroutines:39 SystemTime:2022-07-31T15:49:40.481000763+08:00 LoggingDriver:json-file CgroupDriver:systemd NEventsListener:0 KernelVersion:5.15.0-41-generic OperatingSystem:Ubuntu 22.04 LTS OSType:linux Architecture:x86_64 IndexServerAddress:https://index.docker.io/v1/ RegistryConfig:0xc0001de540 NCPU:4 MemTotal:8302116864 GenericResources:[] DockerRootDir:/var/lib/docker HTTPProxy: HTTPSProxy: NoProxy: Name:nm Labels:[] ExperimentalBuild:false ServerVersion:20.10.17 ClusterStore: ClusterAdvertise: Runtimes:map[io.containerd.runc.v2:{Path:runc Args:[]} io.containerd.runtime.v1.linux:{Path:runc Args:[]} runc:{Path:runc Args:[]}] DefaultRuntime:runc Swarm:{NodeID: NodeAddr: LocalNodeState:inactive ControlAvailable:false Error: RemoteManagers:[] Nodes:0 Managers:0 Cluster:<nil> Warnings:[]} LiveRestoreEnabled:false Isolation: InitBinary:docker-init ContainerdCommit:{ID:10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 Expected:10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1} RuncCommit:{ID:v1.1.2-0-ga916309 Expected:v1.1.2-0-ga916309} InitCommit:{ID:de40ad0 Expected:de40ad0} SecurityOptions:[name=apparmor name=seccomp,profile=default name=cgroupns] ProductLicense: Warnings:[]}
INFO[0000] Setting cgroupDriver systemd
INFO[0000] Docker cri received runtime config &RuntimeConfig{NetworkConfig:&NetworkConfig{PodCidr:,},}
INFO[0000] Starting the GRPC backend for the Docker CRI interface.
INFO[0000] Start cri-dockerd grpc backend
我们看到,它已经连上了docker的endpoint。
这时我们再另起一个终端,启动集群。
需要注意,在清理集群时,要添加一个socket参数,如
kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock。
> kubeadm init --config kubeadm1.24.3.conf
[init] Using Kubernetes version: v1.24.0
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: blkio
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
...
在cri-dockerd的终端中,有了新的输出:
INFO[0000] Start cri-dockerd grpc backend
INFO[0157] Will attempt to re-write config file /var/lib/docker/containers/000f099fa98530c39e69458881c051f25200feb4f25dfd3d8f02f7444e6763ac/resolv.conf as [nameserver 192.168.153.2 nameserver 192.168.153.2 search ]
INFO[0157] Will attempt to re-write config file /var/lib/docker/containers/ed0aa34e77adbf4ff444998b75e2365f1ebe44e831cdf4c55d3eecd4b6582958/resolv.conf as [nameserver 192.168.153.2 nameserver 192.168.153.2 search ]
INFO[0157] Will attempt to re-write config file /var/lib/docker/containers/3431d46d839451adc30f1c44994990daed5b24899959aae34b5cfd3d5c695fc6/resolv.conf as [nameserver 192.168.153.2 nameserver 192.168.153.2 search ]
INFO[0157] Will attempt to re-write config file /var/lib/docker/containers/50ae6ccb6e7c1420f58c1873bf2c17e291a26597a3b042b0df86a1ef2729470c/resolv.conf as [nameserver 192.168.153.2 nameserver 192.168.153.2 search ]
ERRO[0167] ContainerStats resp: {0xc00098ea80 linux}
ERRO[0168] ContainerStats resp: {0xc00098f440 linux}
ERRO[0168] ContainerStats resp: {0xc000791b00 linux}
然而这里还报出一些奇怪的错误。
我们查看docker容器:
> docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
bbded4be83db a4ca41631cc7 "/coredns -conf /etc…" 2 minutes ago Up 2 minutes k8s_coredns_coredns-74586cf9b6-s6n6g_kube-system_68e930db-ac76-4995-bef2-a9f094b5cf88_0
173154bfdc43 a4ca41631cc7 "/coredns -conf /etc…" 2 minutes ago Up 2 minutes k8s_coredns_coredns-74586cf9b6-wstwx_kube-system_178e7a4e-3c35-42e6-b78b-1053274d9d4d_0
fb2810fe84a3 77b49675beae "/usr/local/bin/kube…" 2 minutes ago Up 2 minutes k8s_kube-proxy_kube-proxy-fpfq7_kube-system_3a52d7e5-ffa8-4193-a2de-948861818bf0_0
640f6546ff97 registry.aliyuncs.com/google_containers/pause:3.7 "/pause" 2 minutes ago Up 2 minutes k8s_POD_coredns-74586cf9b6-s6n6g_kube-system_68e930db-ac76-4995-bef2-a9f094b5cf88_0
8933a7f18e54 registry.aliyuncs.com/google_containers/pause:3.7 "/pause" 2 minutes ago Up 2 minutes k8s_POD_coredns-74586cf9b6-wstwx_kube-system_178e7a4e-3c35-42e6-b78b-1053274d9d4d_0
c2319d389da4 registry.aliyuncs.com/google_containers/pause:3.7 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-proxy-fpfq7_kube-system_3a52d7e5-ffa8-4193-a2de-948861818bf0_0
c441aae26e22 88784fb4ac2f "kube-controller-man…" 2 minutes ago Up 2 minutes k8s_kube-controller-manager_kube-controller-manager-nm_kube-system_0b57267fec9fa21f5d899c064341d122_0
c2251251c6be e3ed7dee73e9 "kube-scheduler --au…" 2 minutes ago Up 2 minutes k8s_kube-scheduler_kube-scheduler-nm_kube-system_4b1a2622b0a7caad68556441288e8374_0
90df81c294fc aebe758cef4c "etcd --advertise-cl…" 2 minutes ago Up 2 minutes k8s_etcd_etcd-nm_kube-system_c305f8ecb58a3de0b142aa31e3c6e6cc_0
d14f4a822e37 529072250ccc "kube-apiserver --ad…" 2 minutes ago Up 2 minutes k8s_kube-apiserver_kube-apiserver-nm_kube-system_a38fd4cf236ff9d9bba5bb8f006ffdfd_0
000f099fa985 registry.aliyuncs.com/google_containers/pause:3.7 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-scheduler-nm_kube-system_4b1a2622b0a7caad68556441288e8374_0
50ae6ccb6e7c registry.aliyuncs.com/google_containers/pause:3.7 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-controller-manager-nm_kube-system_0b57267fec9fa21f5d899c064341d122_0
ed0aa34e77ad registry.aliyuncs.com/google_containers/pause:3.7 "/pause" 2 minutes ago Up 2 minutes k8s_POD_kube-apiserver-nm_kube-system_a38fd4cf236ff9d9bba5bb8f006ffdfd_0
3431d46d8394 registry.aliyuncs.com/google_containers/pause:3.7 "/pause" 2 minutes ago Up 2 minutes k8s_POD_etcd-nm_kube-system_c305f8ecb58a3de0b142aa31e3c6e6cc_0
系统的组件都启动了。
> kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
> kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-74586cf9b6-vpdp5 1/1 Running 0 33s
kube-system coredns-74586cf9b6-zdfpw 1/1 Running 0 33s
kube-system etcd-nm 1/1 Running 0 46s
kube-system kube-apiserver-nm 1/1 Running 0 49s
kube-system kube-controller-manager-nm 1/1 Running 0 49s
kube-system kube-proxy-gs9lq 1/1 Running 0 33s
kube-system kube-scheduler-nm 1/1 Running 0 46s
加入工作节点。
> kubeadm join 192.168.153.21:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:d1902aa47f486d6fd1d35f7fb92286ffaa39da0437ded9be8d2de5670d52a8ca
Found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the 'criSocket' field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock
我们发现这里出现了运行时冲突,需要指定,这里就直接在命令行指明,如下:
> kubeadm join 192.168.153.21:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:d1902aa47f486d6fd1d35f7fb92286ffaa39da0437ded9be8d2de5670d52a8ca --cri-socket unix:///var/run/cri-dockerd.sock
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: blkio
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
然后,我们看到节点已加入集群:
> kubectl get nodes
NAME STATUS ROLES AGE VERSION
na Ready <none> 2m14s v1.24.3
nb Ready <none> 24s v1.24.3
nm Ready control-plane 7m33s v1.24.3
这里我不解的是,之前设置CNI前,core-dns的状态是pending,而且节点状态也是Not Ready。但是现在却看似一切正常。
我们先使用简单的flannel做集群网络,注意不要忘记修改cidr为集群创建时指定的。
> kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-5v2vn 1/1 Running 0 41s
kube-flannel kube-flannel-ds-bcgwm 1/1 Running 0 41s
kube-flannel kube-flannel-ds-ctt4v 1/1 Running 0 41s
kube-system coredns-74586cf9b6-vpdp5 1/1 Running 0 14m
kube-system coredns-74586cf9b6-zdfpw 1/1 Running 0 14m
kube-system etcd-nm 1/1 Running 0 15m
kube-system kube-apiserver-nm 1/1 Running 0 15m
kube-system kube-controller-manager-nm 1/1 Running 0 15m
kube-system kube-proxy-6px66 1/1 Running 0 9m56s
kube-system kube-proxy-cc4fw 1/1 Running 0 8m6s
kube-system kube-proxy-gs9lq 1/1 Running 0 14m
kube-system kube-scheduler-nm 1/1 Running 0 15m
网络CNI也正常工作了。
然后我们部署一个简单的微服务应用试试。
看似一切正常,但是我发现集群网络出现问题,不能访问service的服务。而且通过-o wide查看Pod发现他们并不在我所指定的CIDR网段,而是在一个奇怪的172网段。
结合上面的,“还没有部署CNI节点和core-dns就Ready”这个奇怪的现象。我认为cri-dockerd的网络配置有问题。于是我又详细查看的参考资料,发现有一个配置和参考资料中的不一样。
并且我们详细查看上面的cri-docker启动日志:
INFO[0000] Docker cri networking managed by network plugin kubernetes.io/no-op
cri-dockerd的网络是由network plugin kubernetes.io/no-op管理的,这是个啥?
CNI
所以,这里就不得不讨论下kubernetes1.24之后的另一个重大改变:在 Kubernetes 1.24 之前,CNI 插件也可以由 kubelet 使用命令行参数 cni-bin-dir 和 network-plugin 管理。Kubernetes 1.24 移除了这些命令行参数, CNI 的管理不再是 kubelet 的工作。
也就是说,kubelet已经从管理CNI中得到了解放。谁来管理cni呢?
容器运行时。
又回到参考资料中对cri-dockerd的配置,是这样写的:
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
对--network-plugin=cni进行了配置。上述cri-dockerd的启动参数中,有一句:
--network-plugin string <Warning: Alpha feature> The name of the network plugin to be invoked for various events in kubelet/pod lifecycle.
于是我按照这个提示找到一篇解读kubelet配置cni的博文,Warning这句话正是原来在kubelet代码中的(见kubernetes/k8s CNI分析-容器网络接口分析)。
kubelet网络插件有下面三种类型:
- cni
- kubenet
- noop:不配置网络插件
这样我们就明白了,在最初启动cri-dockerd的日志就表示我们并没有给cri-dockerd配置网络插件INFO[0000] Docker cri networking managed by network plugin kubernetes.io/no-op,结合它的启动参数--network-plugin,因此这个问题应该就是出于此。
再次启动集群
我们先清除集群环境,包括flannel网络环境。
在启动cri-dockerd的命令中加上网络插件参数。
> cri-dockerd --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7 --network-plugin=cni
INFO[0000] Connecting to docker on the Endpoint unix:///var/run/docker.sock
INFO[0000] Start docker client with request timeout 0s
INFO[0000] Hairpin mode is set to none
INFO[0000] Loaded network plugin cni
INFO[0000] Docker cri networking managed by network plugin cni
INFO[0000] Docker Info: &{ID:HEPZ:PXCZ:XHZR:SKBX:TJL5:EG5L:U6P3:PI5A:PVZZ:ASKB:QJUC:QEDR Containers:16 ContainersRunning:12 ContainersPaused:0 ContainersStopped:4 Images:15 Driver:overlay2 DriverStatus:[[Backing Filesystem extfs] [Supports d_type true] [Native Overlay Diff true] [userxattr false]] SystemStatus:[] Plugins:{Volume:[local] Network:[bridge host ipvlan macvlan null overlay] Authorization:[] Log:[awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog]} MemoryLimit:true SwapLimit:true KernelMemory:false KernelMemoryTCP:false CPUCfsPeriod:true CPUCfsQuota:true CPUShares:true CPUSet:true PidsLimit:true IPv4Forwarding:true BridgeNfIptables:true BridgeNfIP6tables:true Debug:false NFd:89 OomKillDisable:false NGoroutines:83 SystemTime:2022-07-31T16:59:32.329402283+08:00 LoggingDriver:json-file CgroupDriver:systemd NEventsListener:0 KernelVersion:5.15.0-41-generic OperatingSystem:Ubuntu 22.04 LTS OSType:linux Architecture:x86_64 IndexServerAddress:https://index.docker.io/v1/ RegistryConfig:0xc000468a10 NCPU:4 MemTotal:8302116864 GenericResources:[] DockerRootDir:/var/lib/docker HTTPProxy: HTTPSProxy: NoProxy: Name:nm Labels:[] ExperimentalBuild:false ServerVersion:20.10.17 ClusterStore: ClusterAdvertise: Runtimes:map[io.containerd.runc.v2:{Path:runc Args:[]} io.containerd.runtime.v1.linux:{Path:runc Args:[]} runc:{Path:runc Args:[]}] DefaultRuntime:runc Swarm:{NodeID: NodeAddr: LocalNodeState:inactive ControlAvailable:false Error: RemoteManagers:[] Nodes:0 Managers:0 Cluster:<nil> Warnings:[]} LiveRestoreEnabled:false Isolation: InitBinary:docker-init ContainerdCommit:{ID:10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 Expected:10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1} RuncCommit:{ID:v1.1.2-0-ga916309 Expected:v1.1.2-0-ga916309} InitCommit:{ID:de40ad0 Expected:de40ad0} SecurityOptions:[name=apparmor name=seccomp,profile=default name=cgroupns] ProductLicense: Warnings:[]}
INFO[0000] Setting cgroupDriver systemd
INFO[0000] Docker cri received runtime config &RuntimeConfig{NetworkConfig:&NetworkConfig{PodCidr:,},}
INFO[0000] Starting the GRPC backend for the Docker CRI interface.
INFO[0000] Start cri-dockerd grpc backend
可以看到INFO[0000] Loaded network plugin cni。
在另一个终端里,初始化集群,并安装flannel插件。
> kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-74586cf9b6-2p28x 0/1 Pending 0 46s
kube-system coredns-74586cf9b6-lkrn6 0/1 Pending 0 46s
kube-system etcd-nm 1/1 Running 0 58s
kube-system kube-apiserver-nm 1/1 Running 0 58s
kube-system kube-controller-manager-nm 1/1 Running 0 59s
kube-system kube-proxy-qcgfk 1/1 Running 0 46s
kube-system kube-scheduler-nm 1/1 Running 0 58s
> kubectl get node
NAME STATUS ROLES AGE VERSION
na NotReady <none> 10s v1.24.3
nb NotReady <none> 13s v1.24.3
nm NotReady control-plane 2m34s v1.24.3
> kubectl apply -f ../network/flannel.yaml
namespace/kube-flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
> kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-2rcs4 1/1 Running 0 19s
kube-flannel kube-flannel-ds-9szxg 1/1 Running 0 19s
kube-flannel kube-flannel-ds-cxw5k 1/1 Running 0 19s
kube-system coredns-74586cf9b6-2p28x 1/1 Running 0 3m22s
kube-system coredns-74586cf9b6-lkrn6 1/1 Running 0 3m22s
kube-system etcd-nm 1/1 Running 0 3m34s
kube-system kube-apiserver-nm 1/1 Running 0 3m34s
kube-system kube-controller-manager-nm 1/1 Running 0 3m35s
kube-system kube-proxy-7lsdq 1/1 Running 0 77s
kube-system kube-proxy-fb96h 1/1 Running 0 74s
kube-system kube-proxy-qcgfk 1/1 Running 0 3m22s
kube-system kube-scheduler-nm 1/1 Running 0 3m34s
> kubectl get node
NAME STATUS ROLES AGE VERSION
na Ready <none> 76s v1.24.3
nb Ready <none> 79s v1.24.3
nm Ready control-plane 3m40s v1.24.3
安装flannel前,core-dns为pending、节点为NotReady。安装后正常,这是符合预期的。
并且cri-dockerd中也打印了cni的信息:
INFO[3090] Using CNI configuration file /etc/cni/net.d/10-flannel.conflist
INFO[3095] Using CNI configuration file /etc/cni/net.d/10-flannel.conflist
再次部署用于测试的服务,一切正常:
> kubectl get pods -o wide -n cinema
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
bookings-78c77d68f9-j5jzf 1/1 Running 0 17s 10.5.2.2 na <none> <none>
mongo-deploy-57dc8c8f49-n6psq 1/1 Running 0 17s 10.5.1.6 nb <none> <none>
movies-6fbc5986b9-vs6j8 1/1 Running 0 17s 10.5.2.3 na <none> <none>
showtimes-56fc847b7-4bq87 1/1 Running 0 17s 10.5.1.4 nb <none> <none>
users-6996b995d4-5l5tq 1/1 Running 0 17s 10.5.2.4 na <none> <none>
website-867ff4b9dd-5zz49 1/1 Running 0 17s 10.5.1.5 nb <none> <none>
> kubectl get svc -o wide -n cinema
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
bookings ClusterIP 10.110.129.6 <none> 8080/TCP 27s app=bookings
mongodb-svc ClusterIP 10.103.92.132 <none> 27017/TCP 27s app=mongodb
movies ClusterIP 10.103.102.97 <none> 8080/TCP 27s app=movies
showtimes ClusterIP 10.96.139.99 <none> 8080/TCP 27s app=showtimes
users ClusterIP 10.106.152.98 <none> 8080/TCP 27s app=users
website NodePort 10.96.103.3 <none> 8080:30021/TCP 27s app=website
到这里,1.24.0版本的集群就正常部署Pod并提供服务了。
一些问题
cri-dockerd报错
虽然目前功能上看来没啥问题,但是cri-dockerd一直打印错误信息:
ERRO[3404] ContainerStats resp: {0xc0003c8900 linux}
ERRO[3404] ContainerStats resp: {0xc0005dcb00 linux}
ERRO[3404] ContainerStats resp: {0xc0003c9c40 linux}
ERRO[3404] ContainerStats resp: {0xc0005dd700 linux}
ERRO[3404] ContainerStats resp: {0xc0007be540 linux}
我尝试在当前版本的源码中需要这句日志的输出位置,结果没有发现。然后在社区中提了这个issue。这个问题和社区中Lots of obscure error logging #85问题大概是一样的,可能是一些测试中的遗留,被误合并到主分支上去了。
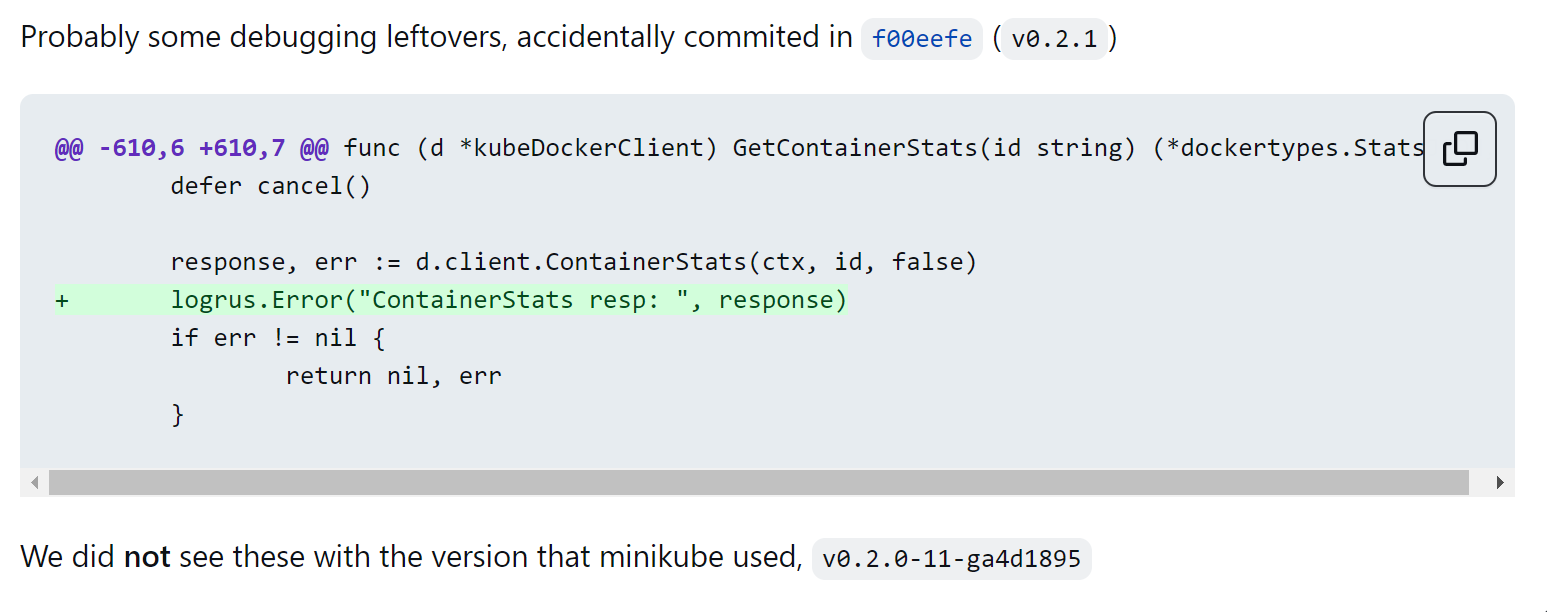
好在容器运行时的功能貌似没有受影响。
cri-dockerd常驻一个终端
这种方法在安装cri-dockerd时将其视为一个软件,必须手动启动它,才可以让它监听socket实现和k8s以及docker的通信。博文基于docker和cri-dockerd部署Kubernetes 1.24中则是使用了另一种方法,并且为我本次的测试提供了很大的帮助。
当然也可以按照cri-dockerd的文档,手动编译、部署。
在博文基于docker和cri-dockerd部署Kubernetes 1.24中,作者的思路与官方的安装思路思路是一样的,即,创建一个可以被systemctl管理的service和socket对。让cri-dockerd在后台启动,不用显式启动并占用一个终端。
其中,关键部分如下。
首先,出于系统通用性,使用cri-dockerd的release中的.amd64.tgz版本。
将文件解压,并将里面的可执行文件移动到/usr/bin/下面。
> tar -xf cri-dockerd-0.2.3.amd64.tgz
> cp cri-dockerd/cri-dockerd /usr/bin/
> chmod +x /usr/bin/cri-dockerd
然后很重要的一步,配置cri-dockerd的启动文件。在/usr/lib/systemd/system/cri-docker.service中写入以下内容:
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
在/usr/lib/systemd/system/cri-docker.socket写入下面内容:
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
关于这两个配置文件,可以参考Linux配置service服务,systemd.socket 中文手册,这篇文章。
然后我们启动这个服务,这样cri-dockerd实际上就有我们刚才创建的名叫cri-docker的service所管理:
systemctl daemon-reload
systemctl start cri-docker
systemctl enable cri-docker
systemctl status cri-docker
这样一来,在每次启动集群前,就不要手动的配置运行cri-dockerd,systemd就帮我们完成这些操作了。
参考资料
- 基于docker和cri-dockerd部署Kubernetes 1.24
- 一文搞懂容器运行时 Containerd
- Open Container Initiative
- 将 Docker Engine 节点从 dockershim 迁移到 cri-dockerd
- 更新:移除 Dockershim 的常见问题
- 检查移除 Dockershim 是否对你有影响
- 排查 CNI 插件相关的错误
- 容器运行时
- 网络插件
- kubernetes-sigs/cri-tools
- Mirantis/cri-dockerd
- k8s卸载flannel网络
- kubernetes/k8s CNI分析-容器网络接口分析
- Linux配置service服务