来源:ACM SoCC'21
作者:Microsoft Research&Stanford University&Microsoft Azure
摘要
-
问题来源:FaaS平台依赖远程存储来维护状态信息,限制了FaaS应用的运行效率。
-
难点:FaaS平台的一些缓存工作尝试解决这个问题,但是由于FaaS应用不同的特点,难以基于业务负载的弹性的调整缓存容量。
-
解决方案:文章提出了Faa$T,一个自动伸缩的分布式FaaS缓存系统:
- 每个FaaS应用有自己的缓存,在被调用、函数被激活时,应用程序从内存加载到缓存;
- 在下一次调用时,可以使用缓存将应用程序“预热”,加快访问速度(冷启动问题?)。
-
缩放依据:根据工作集和对象的大小管理缓存I/O带宽。
-
实验表现:最大提高92%的FaaS应用性能表现(平均57%)。
问题来源
FaaS内存回收和冷启动
FaaS厂商为控制效益,在function不工作时会将其从内存中卸载掉。
Stateless应用的状态维护依赖远端存储
FaaS function通常具有无状态的特点,但在业务中往往需要维护一些状态,例如以下场景:
- 下一次函数的调用需要上一次调用的状态信息;
- 函数pipeline多阶段执行,一个函数的执行需要依赖另一个函数的结果;
这是现实的问题,现有的解决方案是将状态信息写到远端存储中(如Amazon S3),在需要时将其从远端存储读出来。
而远端存储的一个不可避免的问题在于更高的延迟和更低的带宽,同时增加开销和管理成本。
研究现状
本地缓存策略作为缓解上述问题的方案,已经有了初步的解决方案。
现有方案存在如下不足
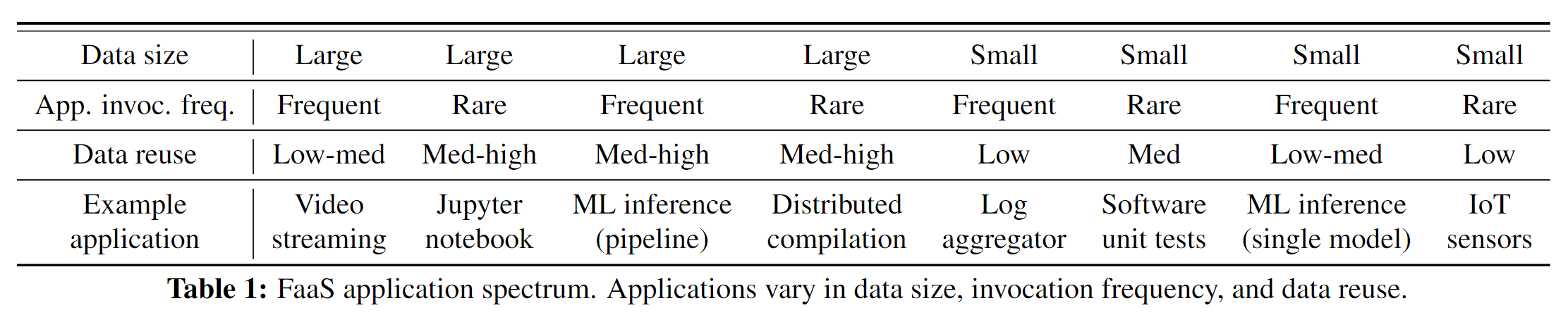
- 为多个应用实现单个缓存,忽略了FaaS应用程序的广泛不同特性。例如很多应用的调用频率非常低[48],为这种应用实现缓存实际上没有必要;但是,如果不为这些应用配置缓存又会影响到服务质量。
- 先前的方案中,要么就是缓存大小是固定的,要么就是缓存伸缩仅根据计算负载。这些方案在数据访问模式稳定和工作集大小小于缓存容量时很有效。
- 没有考虑到大数据对象访问的问题,由于数据量大、VM/容器资源竞争、I/O带宽的限制,在访问大数据对象时会出现性能下降问题。在如机器学习推理这样的大数据量应用中,缓存的横向扩容能使这种服务的性能大大提升。
- 现有的缓存机制对用户来说不透明,需要明确的指定;要么就是提供了一个单独的API来访问缓存。这违背了FaaS平台让用户在管理不必要资源中解脱出来的初衷。
文章做的工作
文章表示,问题的根源在于,Serverless的Cache层从未实现真正的Serverless——与应用程序无感绑定、自动缩放、对上层用户透明。
Faa$T的特性和作用
- 是内存层面的缓存;
- 每个应用将本地Faa$T缓存加载到内存中,缓存在应用程序运行时透明的管理程序所访问的数据;
- 应用从内存中被卸载时,Faa$T也会被卸载(对那些调用频率低的应用来说,在他们很长时间不被调用时,其缓存也会被卸载);
- 该方法消除的对远程缓存存储的需求,减少远程流量开销,降低成本;
- 针对不同的应用提供不同的替换策略和维持策略;
- 应用重新加载时可以预先将最常用的数据加载至缓存中。
- 对缓存的扩缩容策略的方案是:a)为从远程存储中获取大对象增加传输带宽;b)增加经常访问的远程数据的整体缓存大小。
- 对于分布式缓存存储,默认是强数据一致性,一致性和扩展策略也支持自定义。
Contributions
- 通过FaaS提供商的工作负载,总结了数据访问模型;
- 设计和实现了Faa$T,一个透明的FaaS应用自动扩缩容缓存;
- 提出Faa$T扩展策略,根据数据访问模式和对象大小调整带宽和缓存大小;
- 拓宽了可以在FaaS上以接近本机性能运行程序的范围,如ML程序和Jupyter notebook。
对FaaS应用和缓存的分析
表征当前的FaaS应用
文章收集了一段时间内FaaS Provider的日志数据,信息如下。
数据大小
包括20.3million不同的对象,大小有1.9TB。数据访问模式分布如下图:
-
80%的数据大小小于12KB;
-
有25%的数据小于600B;
-
也有很少的一些数据大于1.8GB;
-
对数据的读取次数远远大于对数据的写入次数;
-
虽然应用到后端数据存储有较大的带宽,但对小数据对象大量的访问加剧了存储延迟。
数据访问和重用
下图展示了FaaS应用每次调用访问不同的Blobs(一个存储系统)的比率。
- 大部分应用被调用时只访问一个单独的存储;
- 约11%的应用被调用时访问多个存储系统;
- 超过32%的应用在多次数据访问中访问同一个Blob,更有7.7%的应用在100次调用中访问同一个Blob,还有一个应用在1000次调用中访问一个Blob;
- 大多数应用会使用不超过100个不同的Blobs;
- 所有的数据访问一共涉及到2.6TB的数据,而所有的数据语料只有1.9TB;
- 这意味如果缓存已访问过的数据会节省27%的流量和54.3%的远程存储;
- 跨应用、用户和地区的数据共享情况极为罕见。
时间访问模式
下图展示了每个应用访问Blob的时间维度的模式:X轴是读写Blob函数的调用次数,Y轴是这些调用的到达间隔时间的变异系数(CoV, coefficient of variation),每个点代表具有3次访问次数以上的blob(少于三次不能计算变异系数)。
CoV为1表示到达间隔呈泊松分布,接近0表示周期性到达,大于1表示比泊松到达更大的突发性。
- 可以看出,多数时间访问模式具有突发性的特点。
访问性能
- 写操作通常快于读操作(因为写入操作使用到了buffer,而且不需要在所有实例间同步持久化数据,读数据需要等待存储处理数据);
- 较小的Blob的吞吐量相对较低,因为握手的开销相对于数据量来说过大。
多样的调用模式
- 调用模式的差异较大,81%的应用平均每分钟最多调用一次,更有45%的应用每小时平均调用一次;
- 不到20%的应用产生了99%以上的调用次数,这与在日志中的数据表现一致。
这就带来一个问题,为这些调用次数很少的应用缓存数据可能是浪费的,但这又关系到大部分用户体验。
其他发现
- 超过30%的请求调用相同的数据,这意味着缓存在数据复用上可以产生效果;
- 访问的数据大小跨越了9个数量级,从bytes到GBs;
- 函数调用的频率也有9个数量级的不同。
缓存分析
如果缓存可以起作用,那么应满足如下三个关键条件:
- 数据访问有良好的时间局部性和重用;
- 应同时适用于调用频繁和调用次数很少的应用;
- 缓存应利用空间局部性尽可能减少访问大数据对象的开销。
根据后续分析,还应有以下的特点:
- 缓存还应和应用程序进行绑定,不需要独立管理;
- 缓存还需要对用户透明,并且没有代码入侵性;
- 有多样的伸缩策略,如:a)根据应用负载变化扩展能力?,b)根据数据重用模式改变缓存大小,c)基于访问的数据对象大小改变远程存储带宽。
现有的缓存系统的局限性
下图是一些缓存系统的表征:
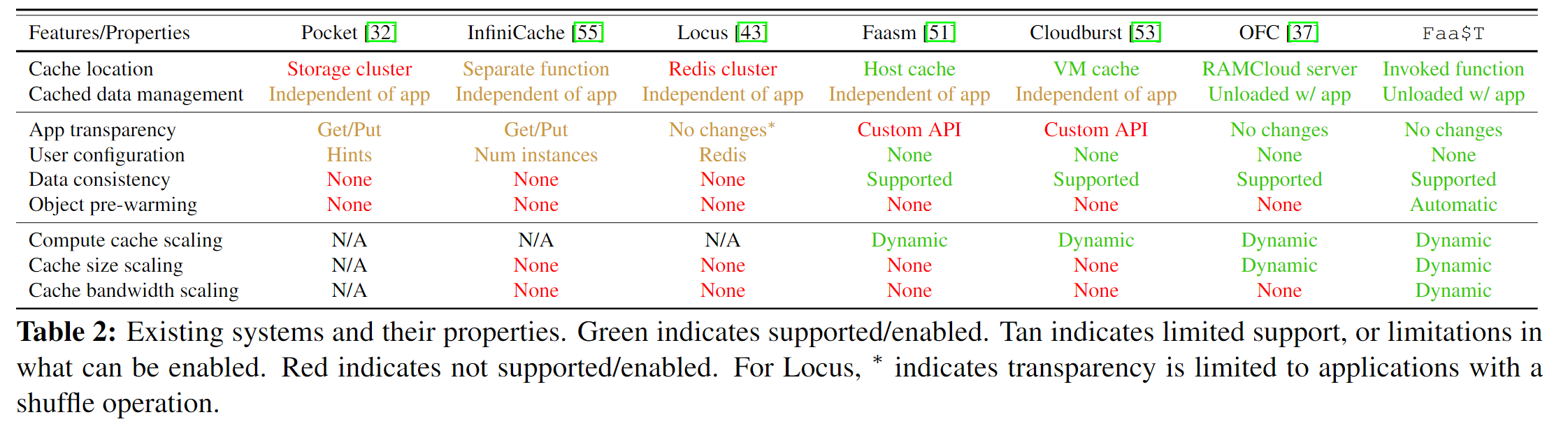
- 缓存系统和应用是分离的,缓存系统独立管理,当应用在内存中卸载时,用户需要额外管理缓存状态或缓存所在的服务,所以缓存还应和应用程序进行绑定;
- 需要进行配置,并表现出代码入侵的现象,需要改动代码来使用缓存,所以缓存还需要对用户透明,并且没有入侵性;
- 在伸缩上仅基于计算负载,但实际的工作情况更加负载,文章建议是缓存层的弹性应考虑以下几点:a)根据应用负载变化扩展能力?,b)根据数据重用模式改变缓存大小,c)基于访问的数据对象大小改变远程存储带宽。
为现有FaaS平台扩展新的应用类型
机器学习推理pipeline
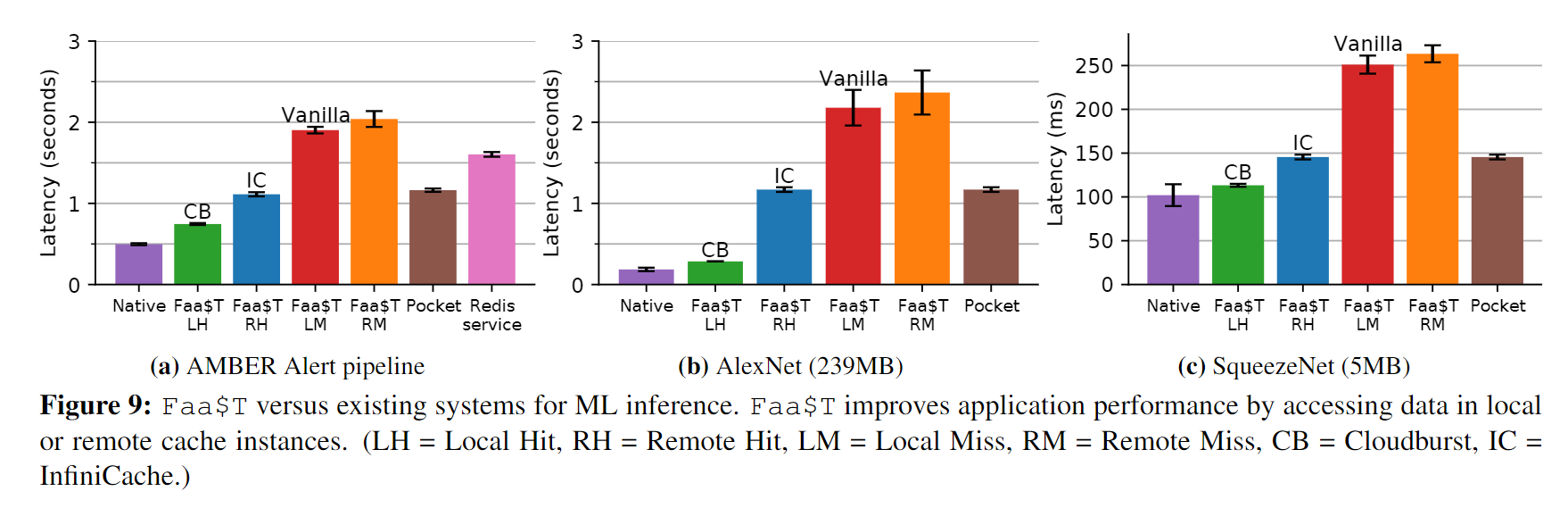
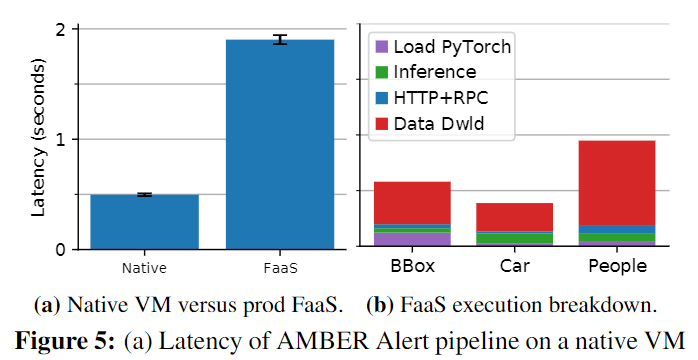
许多业务如健康检查、广告推荐、零售都依赖机器学习。FaaS的按需计算和伸缩很适合ML这种工作负载难以预测的应用。但机器学习需要较低的时延,例如实时人脸识别的需求。下图是一个应用场景:
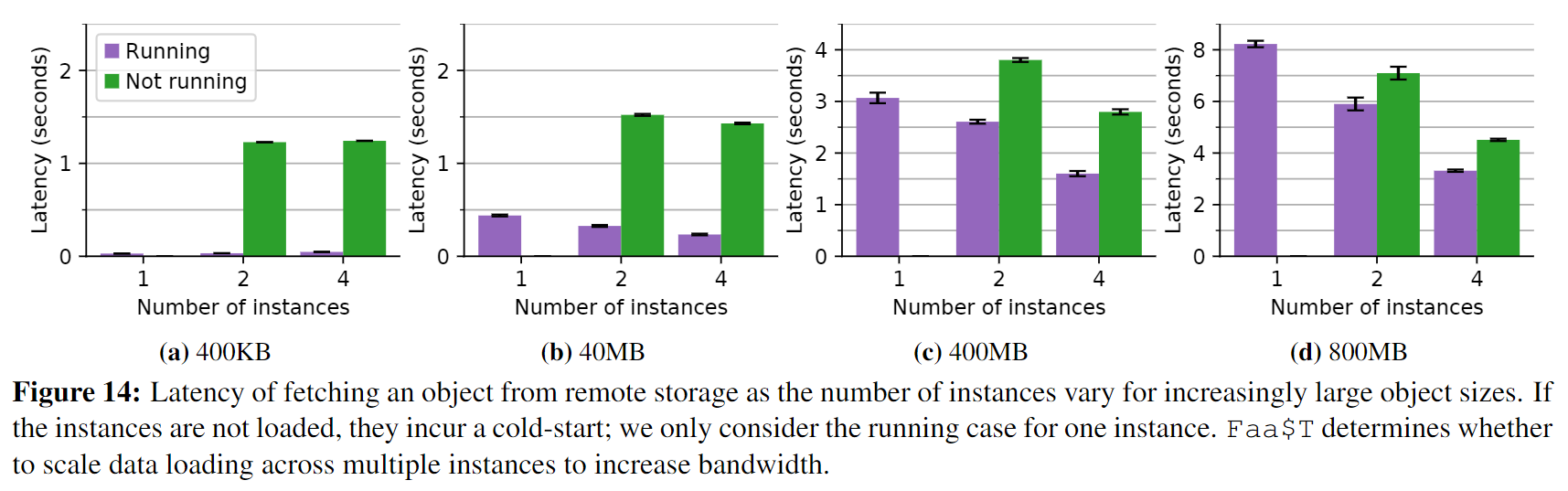
完成这一个场景通常需要秒级的性能甚至不超过1s。文章将上述场景部署在本地的虚拟机和真实的FaaS生产环境中,下图表明在FaaS平台上的速度比本地慢3.8倍,同时可以看出存层存储层的低效是造成延迟的最大因素:
Jupyter notebooks
为验证Jupyter notebooks的性能,文章将其移植到FaaS平台,叫做JupyterLess。每一个cell被看作一个function被调用,cell之间的状态通过共享的中间存储层来保存。文章使用了一个350MB的DataFrame,共10个cell,在本地虚拟机和FaaS平台上进行比较。
由于存在加载中间存储和从远程存储拉取DataFrame的问题,JupyterLess比本地慢63倍。
Faa$T设计
Faa$T缓存在函数执行期间访问的对象,以便可以跨调用重用数据对象。不需要外部存储层和额外的服务,因此可以透明的绑定到应用上(而且是语言无关性)。
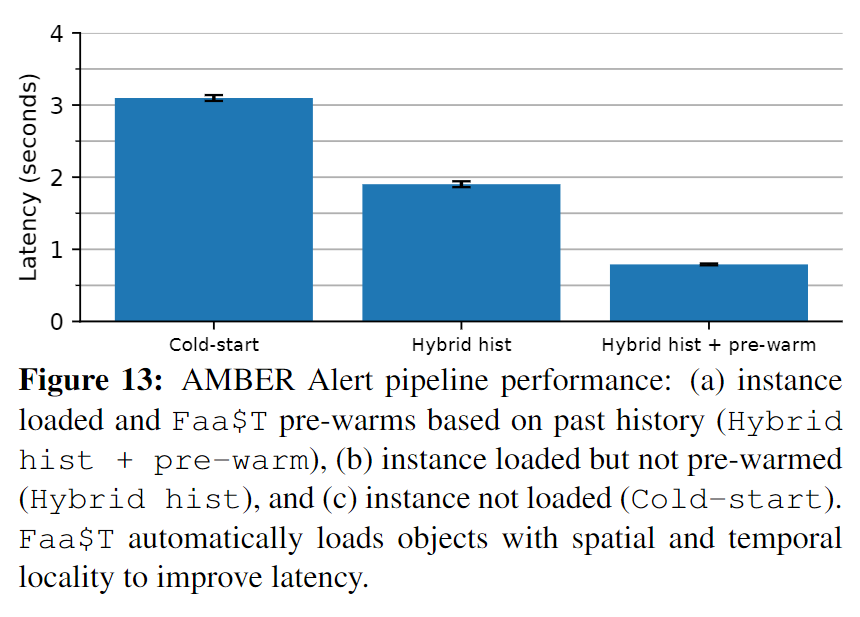
当应用被卸载时,Faa$T收集有关缓存对象的元数据,并在程序重新加载到内存时用其预热缓存中常被访问到的对象,这对调用频繁的应用有很大的帮助。
Faa$T的自动缩放依赖三个方面:
- 基于一个应用每秒被调用的次数,对那些调用频繁的应用非常有必要;(计算维度的伸缩)
- 基于数据重用模式,对涉及到大数据量、大工作集的应用很有必要;(缓存容量维度的伸缩)
- 基于数据对象大小,以扩展远程存储访问的带宽资源,加速应用和远程存储之间的网络I/O;(网络带宽维度的伸缩)。
在应用加载到内存后,Faa$T使用一致散列有效的跨实例定位对象,无需大量的位置数据。
系统架构
下图展示了FaaS平台上的Faa$T的架构:
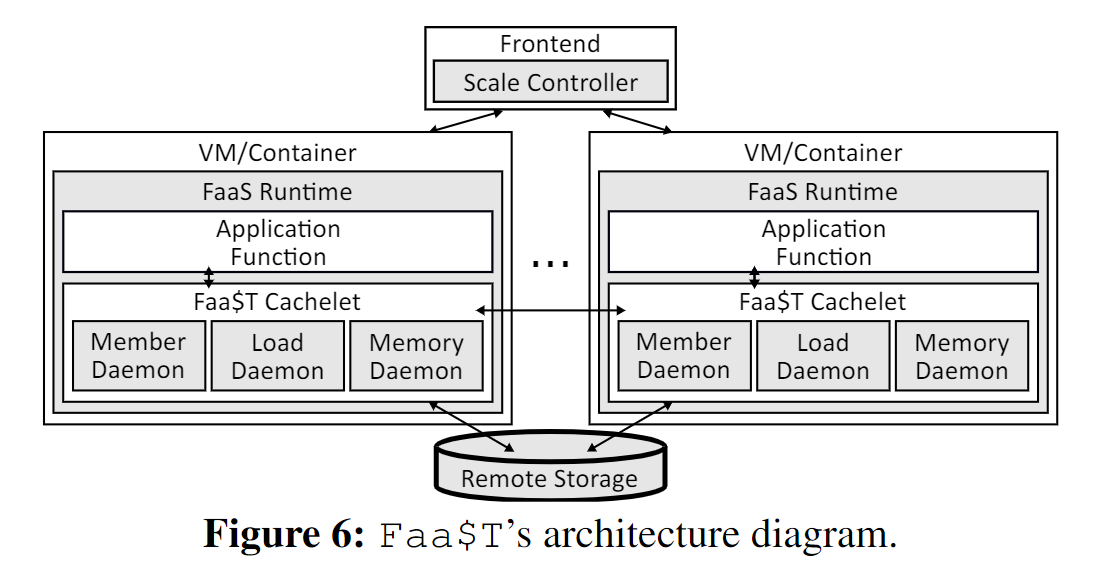
- Faa$T和应用是一对一的,共同运行在FaaS Runtime中;
- Cachelet通过Member Daemon交互,确定数据对象的位置和所有者,所有者负载上传和下载远程数据对象;
- Load Daemon收集缓存对象的元数据,并用来决定在加载应用程序时需要预热哪些数据对象;
- Memory Darmon用来监控函数和缓存的内存消耗,避免内存占用导致应用出现问题;
- Frontend负责将请求负载均衡,Scale Controller负责根据运行时指标来增减实例数量。
访问和缓存数据
读操作
下图为读数据操作:
- local hit:在本地的Faa$T数据缓存中命中;
- local miss:本地的Faa$T缓存中不存在要访问的数据,cachelet会从远程仓库中寻找数据;
- remote hit:在本地的Faa$T缓存中没有找到数据,但是在该数据的所有者的缓存中找到数据;
- remote miss:在本地缓存和数据对象所有者的缓存中均没有命中。
Faa$T使用一致哈希确定对象所有权。
写操作
-
当应用程序需要输出数据时,Faa$T会直接写入数据所有者缓存;
-
执行该函数的实例将数据发送到所有者缓存,然后将其写入远程存储;
-
写缓存和写远程存储是同步写入的。
这保证了所有者始终拥有应用数据的最新版本。应用程序可以将 Faa$T配置为异步写入或根本不写入远程存储。因为Faa$T绑定到每个应用程序,不同的应用程序可以同时使用不同的策略。
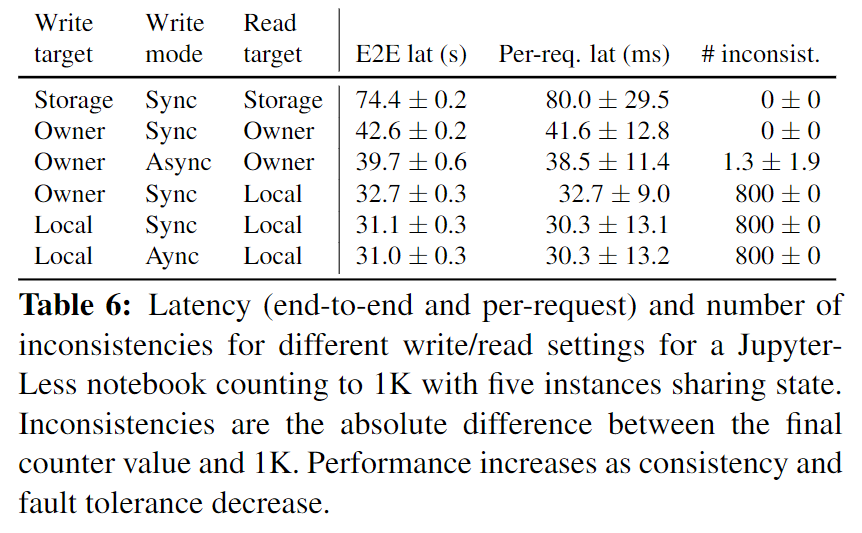
一致性
下图展示了可能发生的读写设置、性能和一致性表现、还有容错情况:
-
默认在读对象时,先验证缓存的版本是否与远程存储的版本是否匹配,在此期间不发生数据传输;如果匹配,不再检索对象是否发生变动,这种验证提供了强一致性保证。
-
但有些应用会放弃强一致性来换取性能。此时,Faa$T可以读取任何缓存版本并异步写入远程存储。这样只能保证最终一致性,允许在某些时刻存在数据不一致的表现。
-
还有,应用程序也可以完全跳过写入远程存储并依赖分布式缓存。
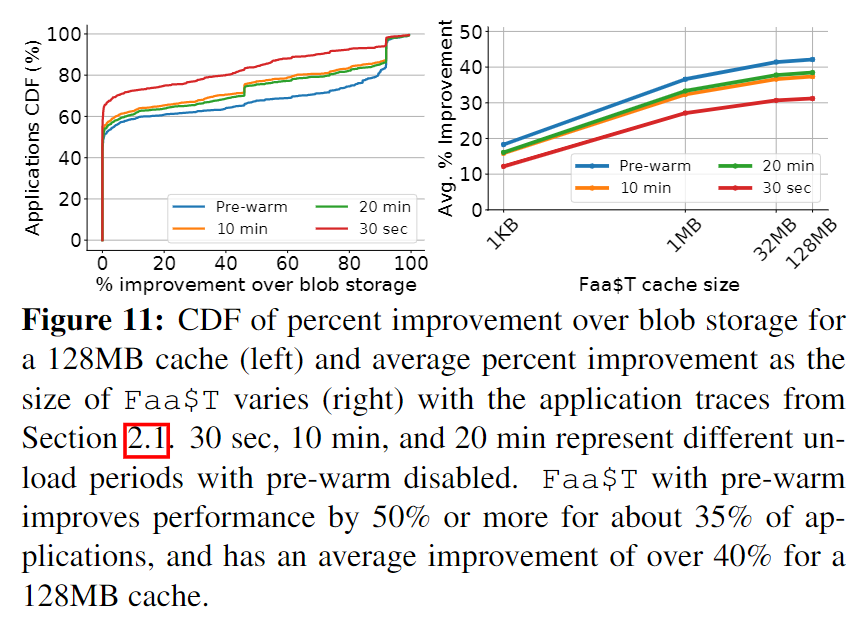
数据预热
为达到这一目的,Faa$T在应用被卸载时,记录了有关缓存的元数据。包括:
- 缓存对象的大小;
- 数据对象的版本;
- 每个访问类型的次数(local hit、remote miss等);
- 对象的平均访问间隔时间等。
使用卸载时间为时间戳,为收集的每个元数据进行标记,以捕获缓存的状态历史。
Faa$T需要决定何时将应用加载到内存中,这里使用了混合直方图策略[48],直方图跟踪应用调用之间的空闲时间,当应用被卸载时,使用直方图预测下一次调用可能到达的时间,并在该事件之前重新加载应用。这也适用于解决冷启动问题。
同时,Faa$T也需要决定将哪些数据对象被加载到新的cachelet中。使用下面两个条件确定需要加载的对象:
- 对象的local或remote命中率大于阈值,就加载该对象;
- 在记录的元数据中多次设计一个对象,就加载该对象。
在Faa$T中清除数据
FaaS应用所拥有的内存是事先规定好的,当函数和缓存对象消耗的内存达到一定数量时,就会将部分数据对象从缓存中剔除。
这里文章实现了两种策略。
- LRU最近最少使用;
- 目标对象的大小大于阈值。
如果需要更多的内存,那么就先使用策略2,再使用策略1。
Faa$T扩缩容
Scale Controller监控了端到端性能和每个应用的工作负载。它也会周期性的询问每个应用是否需要投票以增减实例,正数表示增加实例,负数表示减少实例。
Faa$T有三种缩放类型。
Compute Scaling
基于请求数量、请求处理队列的大小以及平均响应时间,来扩展实例数量。
服务性能下降、请求率过高或者处理队列过长,都会使实例数量增加,反之会减少实例数量。
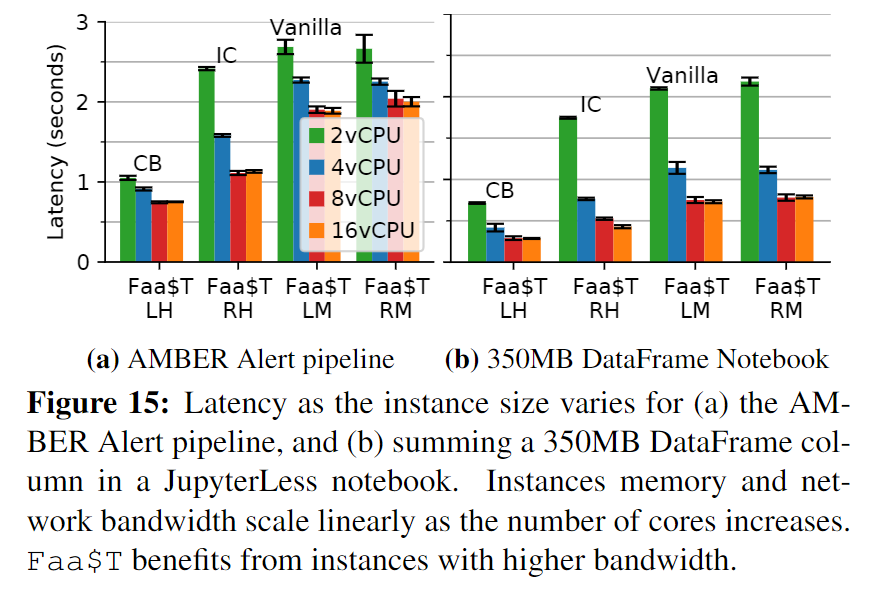
Cache size scaling
Faa$T还可以拓展来匹配工作集大小。例如JupyterLess的一个数据密集型难以提高缓存命中率,因此换入、换出的概率非常高。为解决这个问题,cachelet会跟踪缓存对象换入换出的次数,如果发现这样的情况经常发生,就扩大缓存容量。反之,缩小缓存容量。
Bandwidth scaling
Faa$T 还支持具有大型输入对象的应用程序。对于此类对象,Faa$T 将远程存储的下载平均分配到多个缓存中,以达到两个目的:
- 为远程存储创建更高的累积 I/O 带宽;
- 利用实例之间更高的通信带宽(与每个实例和远程存储之间的带宽相比,实例间的带宽更好,网络I/O更有效率)。
当cachelet接收到对象访问时,使用如下公式计算多个实例和对象大小S的数据传输延迟$T_{DR}$:
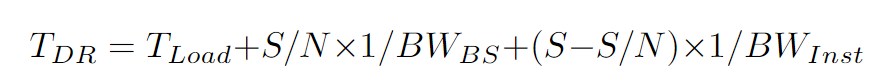
- N:实例数量;
- S:对象的大小;
- $T_{Load}$:实例加载的延迟;
- $BW_{BS}$和$BW_{Inst}$:记录不同的网络和远程存储的带宽。
迭代过程在$T_{DR}$的变化小于10%或$T_{DR}$在迭代过程中增加时停止。
Handling conflicting scaling requests
当扩缩容策略发生冲突时,控制器会优先处理扩容策略,因为这样更加保守。但是,如果所有策略都表明缩减实例不会导致问题时,就会缩容。
Idle function computation resources
在一些情况,实例数量扩容可能会导致资源浪费。此时可以将一些低优先级的任务拿出来运行。
实现
生产级别的FaaS平台
应用包含一个或多个功能,Faa$T透明的加载和管理对象:触发器(接收http request)、数据输入(blob)、输出(消息队列)。用户可在使用时配置Faa$T的一些策略,如扩展策略、一致性策略、缓存置换策略等。
下图展示了应用实例、FaaS Runtime还有function在VM或Docker Container中运行:
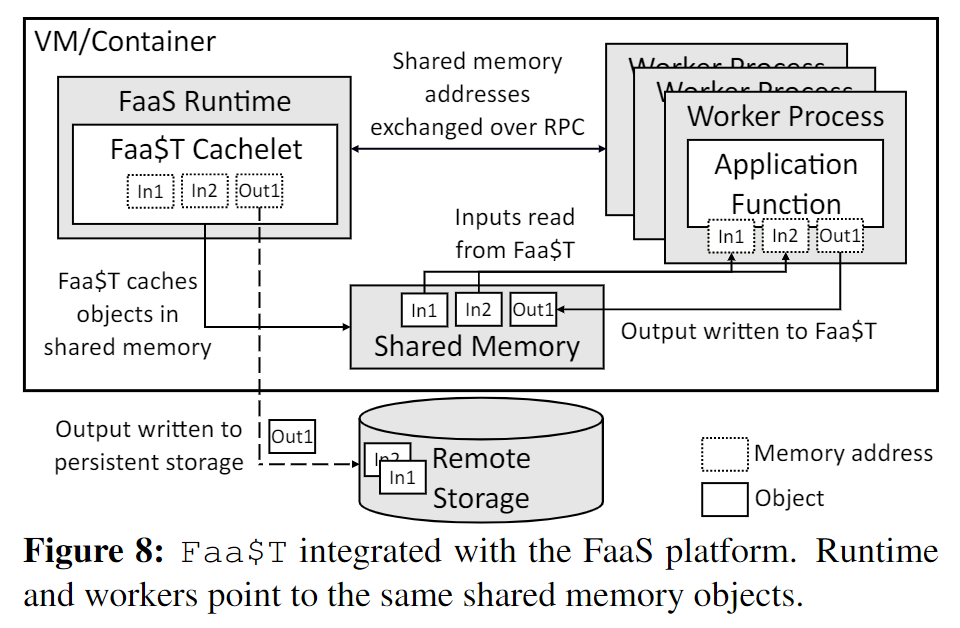
- 接收到请求;
- Runtime收集请求输入并调用function,将参数传递;
- function处理完后,将结果返回给Runtime;
- Runtime继续执行,如将数据写入远程存储或消息队列。
缓存数据
运行时和function使用持久的RPC进行控制和数据交换。共享内存时Faa$T缓存数据的地方,通过传递共享内存中数据的地址,减少端到端时延。
当运行时在调用函数前,准备进行数据绑定时,Faa$T先拦截并检查缓存。当函数产生输出时,Faa$T会缓存起来备用。
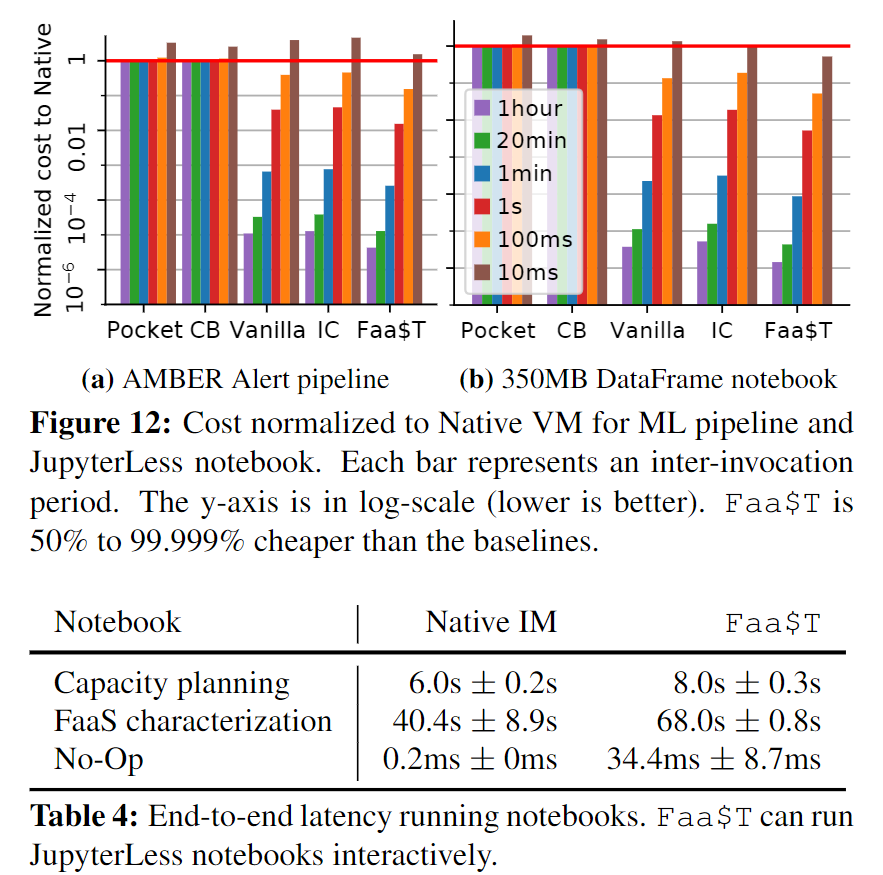
实验评估
两个比较点
- Faa$T给应用带来的性能提升;
- 评估四种缓存访问情况:local hit、local miss、remote hit、remote miss。
六个基准
- 本地的大型虚拟机,所有访问都在本地进行;
- 没有集成Faa$T的大型FaaS平台Vanilla,对象的访问都在远程存储,它的最佳性能表现等同于Faa$T LM;
- InfiniCache[55](IC),为远程实例配置Faa$T,类比Faa$T RH;
- Cloudburst(CB)的存储层,最佳实例表现等同Faa$T LH;
- Pocket,近似于手动管理的Redis VM,所有数据均已内存速度访问;
- 商业级Redis服务。
两个应用
- ML推理应用;
- Jupyter notebook。
主要以程序延迟和成本为指标。对ML应用,使用单模型和带有pipeline的推理。
对于单模型,使用了两个不同的模型,在资源使用和延迟上都有所不同:
- SqueezeNet,5MB;
- AlexNet,239MB。
带有推理管道的模型使用了上面提到的识别汽车和人脸的应用,边界模型(35MB)的输出被输入到人体识别(97MB)和汽车识别(5MB)的模型中。
对于 JupyterLess,有5个notebooks:
- 单消息日志记录;
- 对 350MB 的 DataFrame 列求和;
- 进行数据收集和绘图的能力规划;
- FaaS数据表征特征;
- 计数到 1K。
函数数据对象由每个单元执行后的笔记本状态组成,以 JSON 格式存储。
结果