本篇整理自IEEE CLOUD'21会议中的文章,主题为云背景下的资源管理。
RunWild: Resource Management System withGeneralized Modeling for Microservices on Cloud
⭐摘要
问题背景
微服务内部通信的复杂性,必须考虑资源利用、调度策略和请求均衡之间的平衡,以防止跨微服务级联的服务质量下降。
文章做了什么
提出资源管理系统RunWild,可以控制所有节点涉及到的微服务管理:
- 扩缩容
- 调度
- 自动的根据指定性能表现的负载和性能平衡优化
- 统一的持续部署方案
着重强调了协同metrics感知在预测资源使用和制定部署计划中的重要性。
在IBM云进行实验,以K8s的自动调度为基线,减少P90响应时间11%,增加10%的吞吐率,降低30%的资源使用。
贡献
- 扩展的部署框架:适用于K8s的调度框架,用来在资源分配、部署、和运行时来控制部署机制;
- 通用的建模方法:综合考虑微服务特性、节点的相对独立性、工作负载和全局协同节点状态感知,通过结合聚类和回归技术预测资源使用;
- 微服务间交互指标:一个称为内聚的指标反映了在同一个节点上放置高度相互通信的微服务的优势;
- 通过Service Mesh对运行时工作负载进行分区:利用服务网格操作流量路由,用其控制能力来划分工作负载以匹配资源的分配。
⭐现有技术存在的问题
水平伸缩
- 超过某个阈值时,实例的增多与性能表现的增长不匹配,正如收益递减定律所解释的那样;
- 资源过度分配并不会显著增加性能表现;
- 而资源不足会导致性能下降或者致命错误。
垂直伸缩
- K8s虽然可以支持HPA和VPA,但是不能一起工作,同时进行HPA和VPA难免会造成干扰。
此外,复杂的资源依赖,全局的资源调度策略使得伸缩方案受多方面影响。
文章的动机是识别、描述和管理所有因素和维度,以实现统一的部署解决方案,而不是运行相互干扰的机制。
部署的三个角度
- 所部署的服务的实例副本数;
- 节点上每个实例所得到的资源;
- 每个实例的网络容量。
然后引出下面4个重要的问题:
- 调度所涉及到的策略、资源和具体情景很复杂,要考虑的东西太多;
- 同一节点上部署的服务可能对资源的争用很敏感;
- 微服务之间的通信,亲和性等因素会影响到全局的服务性能表现、响应事件及吞吐量,最好的方式是使部署的微服务减少跨节点的通信;
- 如何将请求负载均衡到不同实例以带来更好的网络表现,虽然Service Mesh能够实现负载的分发,但是难以解决上述问题。
文章列举了一些其他文章做的工作,并对比这些工作解决了上述4个问题中的哪些:
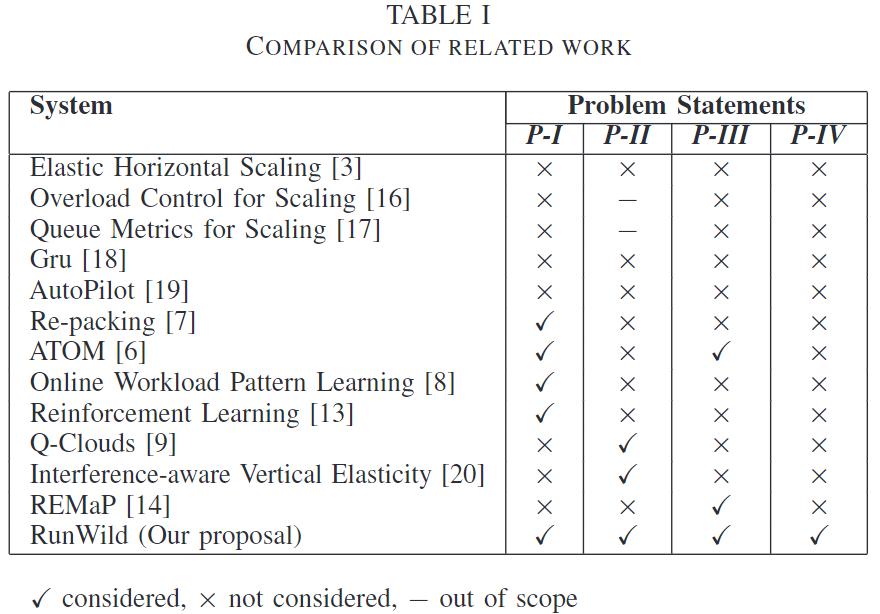
该文会精读,请关注最新的文章。
Fast and Efficient Performance Tuning of Microservices
⭐摘要
针对使用容器部署的微服务架构应用,以Kubernetes、Docker Swarm容器管理平台为依托。在应用正式部署上线之前,也就是在pre-deployment阶段,迭代的根据资源使用相关指标,结合类多目标优化算法(文章称为heuristic optimization algorithm)对资源分配进行调优。
⭐系统架构
- 将应用部署到云平台;
- 进行负载注入;
- 基于Jaeger的监控系统开始进行性能测试和追踪(对每个微服务),收集数据,如响应时间和资源的使用量;
- 通过Jaeger解析服务调用序列;
- 由Tuning Agent参照服务序列信息、不同类别请求的响应时间和平均资源使用进行调优;
- Tuning Agent预估每个微服务的新的CPU配额信息;
- 将这些信息存储到Tuning数据库中;
- 编排器根据这些信息对服务进行迭代部署。
⭐测量、优化的依赖指标
需要对服务进行请求的注入来进行测量,主要指标是服务响应时间。涉及到链路追踪、性能监控。
⭐调优模型抽象
小背景、前提和假设
- 应用需要一些特定的工作负载$W$,这些工作负载发生在特定的情境,例如在线商城的Black Friday。因此,调优过程可以对其他感兴趣的工作负载重放,从而产生一系列特定于工作负载的配置,可以在部署应用程序时适当地使用。
- 本文重点关注CPU资源的限制,但是该模型可以拓展到其他资源。
- 应用包含**$K$个微服务**,每个微服务运行在自己的container中。
- 每个应用支持**$C$种不同的请求类别**。
- 每个请求类别**$c$关联到不同的响应时间$T_c$**。
- 每类请求**$c$涉及到一个微服务调用序列$S_c$**。
- 因此这个序列中每个微服务$k$都涉及到一个CPU需求。
- 主机上对应的服务$k$所需的CPU配额表示为$\alpha_k$。
资源分配问题抽象
问题可以抽象为:在满足响应时间的需求下,求解对每个微服务CPU配额的最小值。
- 目标为最小化CPU配额;
- 需要满足前提条件,即:资源配额能够使某类请求的响应时间$R_c$小于等于目标值$T_c$;
- 其中响应时间$R_c$是工作负载$W$和对$K$个服务CPU配额的函数;
- 最后限制CPU需求总额是有限的。
⭐应用案例及实验
使用的微服务案例Bookstore。
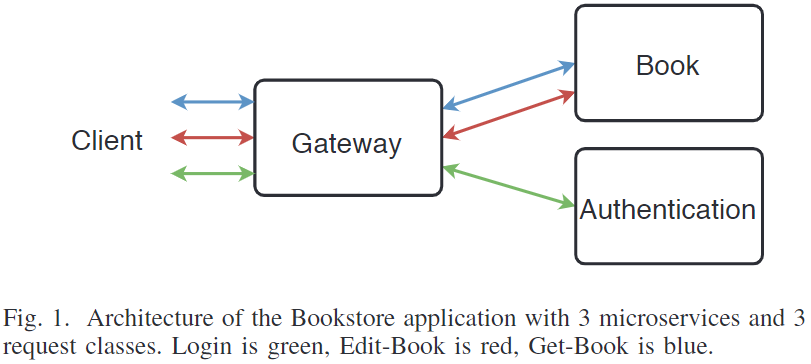
⭐我的问题
工作负载的模拟具体如何实现?
有哪些开源微服务应用真正可用又具有一定的代表性?
Skynet: Performance-driven Resource Management for Dynamic Workloads
⭐摘要
问题背景和主要矛盾
云环境下,资源利用率和应用的性能表现之间的矛盾。
难点
- 用户常会分配过多的资源
- 应用的多样性和动态性,工作负载的动态性及难以预测性
- 性能表现取决于多种不同资源
文章做了什么,怎么做的
提出Skynet,针对上述三个难点,可以自动对云资源进行管理。
-
评估资源需求依赖的指标:Skynet使用performance level objectives(PLOs)准确捕捉用户对所需性能的意图,将用户从资源分配循环中解放。Skynet通过目标PLO去预估资源需求,使用Poportional Integral Derivative(PID)控制器对每个应用调整对应的参数。
-
资源需求计算、分配、调度方法:为捕获每个应用对不同资源依赖,Skynet扩展了传统的一维PID控制器(传统的单输入单输出),实现对CPU、内存、I/O和网络吞吐的预估。Skynet建立一个动态模型,对于每个应用,将目标PLOs映射到资源,同时考虑多种资源和变化的输入负载。事实上,Skynet处于一个动态循环控制来预估资源。
-
实现和评估:在kubernetes中将skynetas实现为端到端的定制调度程序,并在5个节点的私有集群和60个裸金属服务器AWS上使用真实的工作负载对其进行评估。以K8s为基线,PLO违规降低7.4倍,资源利用提高两倍。
⭐系统架构
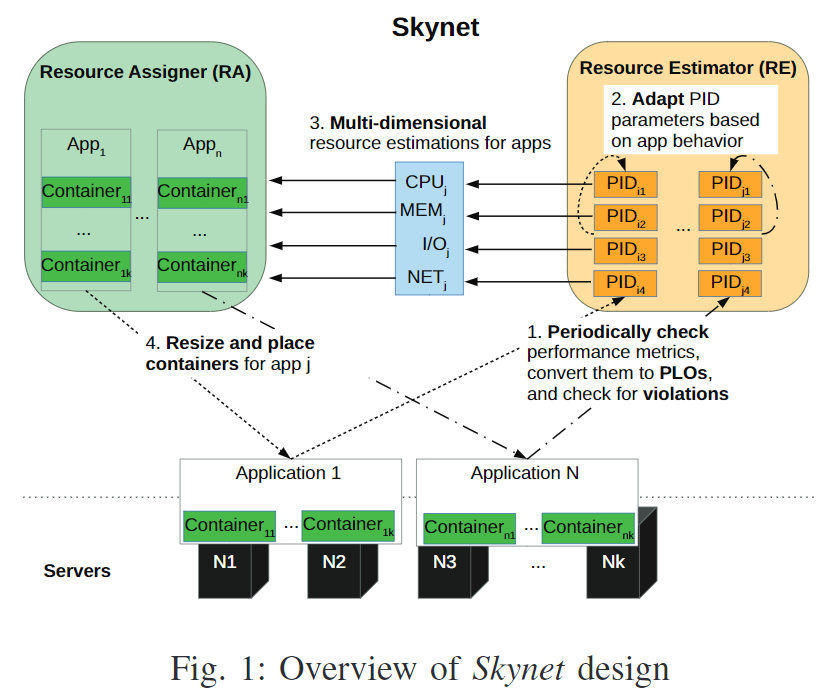
用户可以指定PLOs,明确对吞吐量、延迟、处理时间等指标的需求。Skynet根据这些PLOs,使用PID[41]预估每个应用的资源需求量。动态的将PLO映射到资源需求,这样一来可以让Skynet适应变化的工作负载和每个应用不同的生命阶段。
示例
一个web应用PLO为1000请求/秒。Skynet给每个新应用分配一个预定义容器。在执行阶段,Skynet主要使用两个组件:Resource Estimator(RE)和Resource Assigner(RA),来周期性的调整资源配额以满足PLO:
- Skynet周期性监控应用性能指标,如果触发PLO违规,会触发RE。
- RE基于PLO调整PIDs的参数。
- 基于目标PLO,RE预估应用新的资源需求。
- 当可分配资源满足条件时,RA调整应用容器。
放置应用以及根据控制器更新应用放置
-
确定应用资源需求量后,Skynet决定容器的资源限额和放置。具体来说,包括容器打包,节点绑定以及资源配额。其中,容器大小和放置由于需要考虑多种资源的约束,远比打包应用复杂。放置应用的目标是:避免应用间干扰,提高应用性能表现。
-
当新应用到来时,Skynet进行扫描,查看是否有某个服务节点可以单独满足应用的资源需求,如果不存在这样的服务节点,就迭代执行下列步骤:
- 增加一个容器的数量;
- 在容器之间平均分配资源;
- 找到能够满足容器需求,并且负载最高的服务节点;
- 如果没有,循环执行上述步骤。
-
调整应用资源配额。每次请求改变资源需求时,有三种可能:(理解的有些别扭?)
- 资源不够。该情况下,Skynet决定有没有现存的容器可以移除。然后基于节点负载对节点进行排序,移除额外的容器。
- 节点上的可用资源早已被分配给应用。Skynet在容器之间平均增加应用程序的资源,以匹配新的请求。
- 可用资源分布在不同的服务节点上。Skynet以放置新应用的思路放置新的容器。
总的说,就是处理,容器应该放置在哪个节点上的问题。算法思路如下:

在Kubernetes上的实现
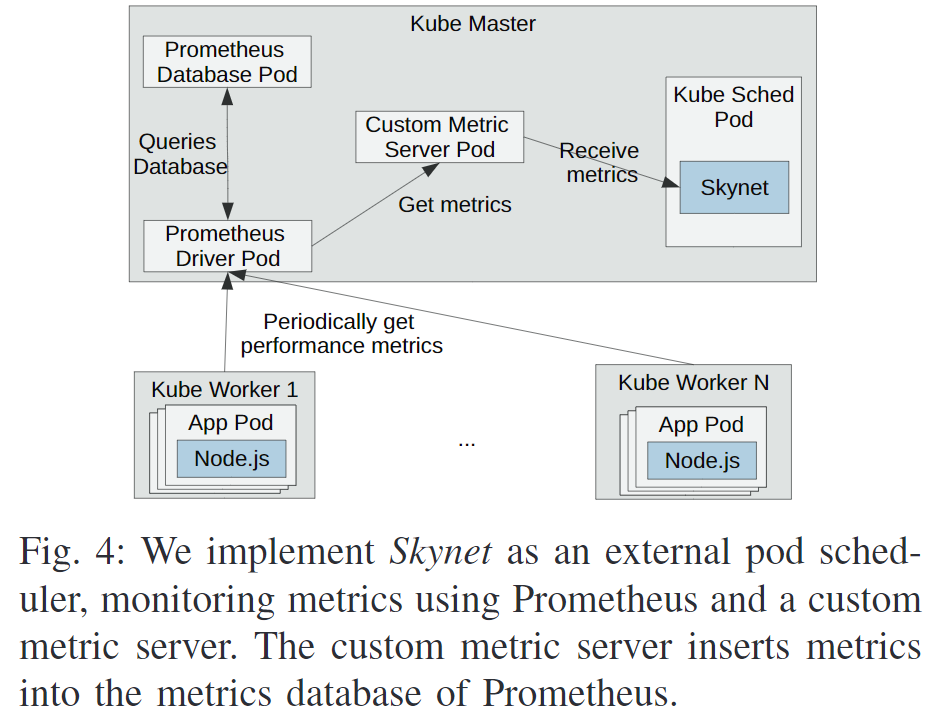
使用Golang实现自定义调度器。使用Prometheus进行监控。代码开源[11]。
⭐我的问题
关于PID控制理论的补充
已经不止一次在论文中看到使用PID来调整资源分配了。
如果要使用PID算法,再细读
获得监控数据后具体怎处理?
分配资源的具体方法?
Konveyor Move2Kube: AutomatedReplatforming of Applications to Kubernetes
⭐摘要
文章提出Move2Kube,一个再部署框架,能够自动调整部署细节,并通过部署pipeline将非Kubernetes平台部署的应用转移到Kubernetes平台上,同时最小限度修改应用架构和实现。
此外,文章提出
- 一个最小化的中间表示,不同的应用部署构建都可以转化到这个中间表示上来。
- 一个扩展框架,用于添加对新的部署源平台和目标中间件的支持,同时允许定制化。
Move2Kube已经开源:https://move2kube.konveyor.io/
要解决什么问题
在不是K8s平台部署的应用迁移到K8s平台上,同时应该最小限度的修改原系统的实现和软件架构。
挑战、难点在哪里
- 应用规模:企业级应用往往有上千个组件,人工迁移费时费力;
- 应用异构:多样的部署平台,多样的应用架构和种类;
- 不同的代码源、组件仓库:代码源或者使用的组件分布在不同的仓库中,很难将其组织到一起,如何分布的数千个目录中找到正确的文件很有挑战;
- 容器化挑战:将应用容器化时,对于优化配置和分层安全很有必要,需要对容器内部、镜像技术和应用配置有深入的理解;
- 目标平台映射:找到正确的不同平台的配置映射关系是困难的,例如如何选择从简单的K8s service转换到Istio的配置中;
- 应用的最佳实践:K8s有最佳实践[6],如何确保迁移使用K8s的最佳实践;
- 定制化的需求和有效的Day 2 Operation:针对不同应用和需求定制化的配置以适应平台特性需要一定的经验和时间,同时需要考虑Day 2 Operation。
关于什么是Day 2 Operation:https://jimmysong.io/blog/what-is-day-2-operation/
Move2Kube
这个开源框架旨在解决应用迁移到Kubernetes平台过程中出现的上述问题。它提供了标准化的Pipeline,包括容器化、参数化、配置优化、定制化等解决方案,满足面向特定平台的多源、多服务的应用部署迁移。
该文不太属于资源管理方面。