概念
作为目前最流行的时序数据库之一,InfluxDB常用于监控系统数据采集。在使用它之前,我们需要了解一些InfluxDB的概念。以下内容多翻译自官方文档。
InfluxDB数据元素
以下数据元素为InfluxDB2.0版本所包含的。
bucket中的数据大概长这个样子:

Timestamp
所有存储在InfluxDB中的数据都有一个_time列来存储时间戳。时间戳存储为纳秒的形式。其日期和时间显示格式为RFC3339UTC时间,如2020-01-01T00:00:00.00Z。在写入数据时,时间戳的精度很重要。
Measurement
_measurement列作为tags、fields以及timestamps的容器,它是个字符串。我们可以把它理解为表名(如果按照关系型数据库如MySql,它更像表名,代表一张表所记录的内容),就上面的图中,可以说_measurement census所代表的是对指标bees、ants的记录。
Fields
一个field包含一个字段键,存储在_field列中;以及一个字段值,存储在_value列中。就上面图而言,有字段bees=23, ants=30等4个fields。
Field key
字段的键表示字段名称,如bees, ants这两个键。
Field value
字段的值。值的类型可以是strings、floats、integers或是booleans。例如,bees在不同时间的值是23,28。
Field set
字段集合指的是同一个时间戳下面的一组键值的集合,例如时间戳2019-08-18T00:00:00Z这个时间戳对应的Field set为:census bees=23,ants=30
需要注意的是,
Fields是不被索引的,因此使用Fields做为查询条件是需要遍历大量的数据,造成查询效率低下。所以需要使用tags做为查询条件,它会被索引。因此我们将经常需要查询的元数据放在tags中,以加速查询效率。
Tags
上图中的location和scientist以及它们对应的值都是标签。标签包含标签的键及标签的值,也是以key-value形式存储。
Tag key
上图中的location和scientist为标签的key。Tag key类型为string。
Tag value
上图中location有两个值,为klamath以及 portland。Tag value类型为string。
Tag set
Tag键值对的集合为Tag set。上图中包含的Tag set包含四组标签键值对。
location = klamath, scientist = anderson
location = portland, scientist = anderson
location = klamath, scientist = mullen
location = portland, scientist = mullen
Tags是被索引的,同时Tags也是可选的。对Tags的查询要比Fields快。
那么,Tags应该如何设计以适应它常用做查询的条件呢?
Tags应该包含高度可变,特殊的信息,如UUID、哈希或者随机字符串,能够在数据库中对某条记录有特殊的标识。
Bucket schema
我们先来理解下为什么在InfluxDB中schema是个很重要的概念。例如我们重点查询的数据在fields中,下面是查询bees=23的数据:
from(bucket: "bucket-name")
|> range(start: 2019-08-17T00:00:00Z, stop: 2019-08-19T00:00:00Z)
|> filter(fn: (r) => r._field == "bees" and r._value == 23)
InfluxDB将会便利每一个field的值,找到所有的结果再返回。当我们的measurement 有几百万的数据列是,这非常花时间。
因此,为了优化查询,我们可以使用schema改变这些fields(如bees和ants),让它们变成tags,同时让原本的tags变为fields。数据就会变成下面的样子:
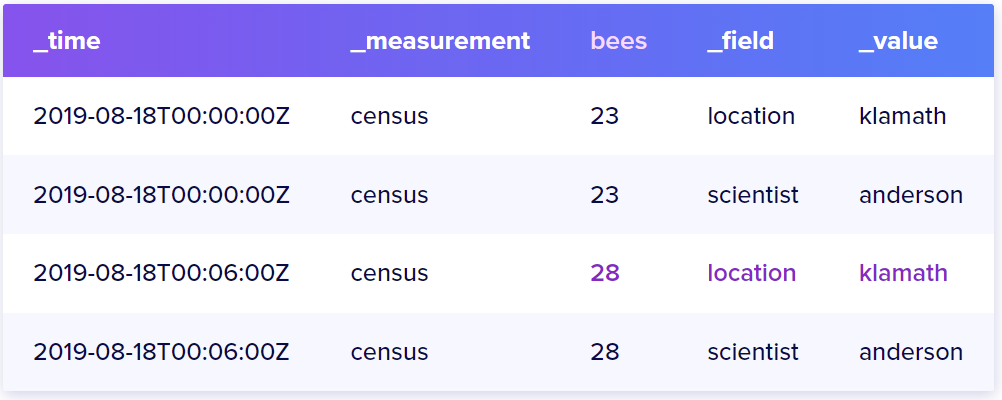
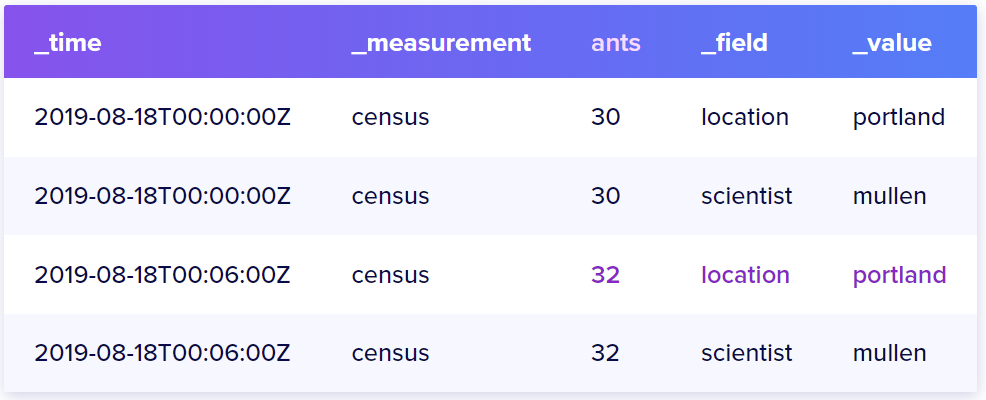
这样就加快了数据查询效率。
通常,一个有详细的schema-type的bucket指的是,这个bucket中的每一个measurement都有一个明确的schema。这个schema限制了数据写入measurement的形式。
例如,下面的schema用来限制measurement census的数据:
Series
Serices包含series以及series key两个概念。
首先,一个series key是一系列点的集合,这些数据点共享同一个measurement、tag set以及field key。例如,示例数据中包含下面两个不同的series key:
换句话说,一个series key所包含数据有相同的measurement、tag set以及field key,这些数据最大的不同就是field value。这这一组相同的measurement、tag set以及field key就组成了一个series的series key。
而series是一个series key对应的数据序列,序列中的数据包含timestamp以及field value。下面是一对series key - series的例子:
# series key
census,location=klamath,scientist=anderson bees
# series
2019-08-18T00:00:00Z 23
2019-08-18T00:06:00Z 28
好好理解Series的概念,这个对于设计如何存储数据很有帮助(如哪些数据应该存放在Fields中哪些可以放在Tags中)。
Point
一个point包含一个series key,一个field value以及一个timestamp,我们可以把它理解为一条数据记录,如2019-08-18T00:00:00Z census ants 30 portland mullen。
Bucket
所有的InfluxDB中的数据都存储在bucket中。Bucket结合了数据库以及数据保留期这两个概念。此外,一个bucket属于一个organization。
Organization
一个organization是一个用户团体的工作空间。InfluxDB中的dashboard、tasks、buckets以及users这些概念都要属于一个organization。
InfluxDB数据组织形式
原文是“data schema”,我将其理解为数据的组织形式,或是模式、规范。
InfluxDB使用**time-structured merge tree(TSM)这个数据结构存储数据,同时使用了time series index(TSI)**有效的压缩数据。
此外,InfluxDB提供了扁平化的数据组织形式,包括下面几部分:
- Annotation rows
- Header row
- Data rows
- Other columns
- Group keys
这样的数据组织形式多用于查看原始数据、或是以CSV格式的返回数据。
Annotation rows
注释行描述了列的熟悉,如:
#group#datatype#default
Header row
标头行定义了列的标签,描述每一列数据的含义,就是列名,如:
table_time_value_field_measurement- 还有tag key的名字,如
tag-1,tag-2
Data rows
每个数据行包含header row所指明的数据,一行是一个point。
Other columns
下面几个列是可选的,用来附加一些数据信息:
annotationresulttable
Group keys
决定数据聚合内容。关于Grouping操作看这里。
InfluxDB的设计准则
了解这些设计准则,我们能够更高效的使用它,能够合理的设计我们的数据存取方法。
Time-ordered data
为提升性能,数据以时间升序的顺序写入。
Strict update and delete permissions
为增加查询和写入性能,InfluxDB严格限制了更新和删除操作的权限。它所写入的时序数据几乎都是不会修改的最新的数据。因此更新和删除这两个动作在时序数据库中显得有些特殊。
Handle read and write queries first
相对于强一致性而言,InfluxDB会优先处理读写请求。任何影响查询数据的事务执行优先级都是靠后的,以确保数据的最终一致性。例如,我们写入数据的频率特别高,每毫秒要写入多条数据,那么在写数据过程中读数据,就有可能读不到最新的数据。
Schemaless design
InfluxDB使用“schemaless”的设计来更好的管理断断续续的数据。例如,一个程序运行几十分钟然后结束了,我们所记录的数据也就在这几十分钟范围内。
Datasets over individual points
通常讲,时序数据集整体比单个点的数据要重要。InfluxDB实现了强大的工具来聚合数据和处理大型数据集。而每条数据通过timestamp以及series来区分,所以InfluxDB中没有传统场景中的IDs(或者理解为主键)这一概念。
Duplicate data
为简化冲突的解决和提高写性能,InfluxDB对相同的point不会存储两次。如果某个point的一个新的field value被提交,InfluxDB会将该point对应的field value设置为最新的那一个。在极少数情况下数据可能会被覆盖。关于重复数据的更多信息看这里。
Go Client
在了解InfluxDB基本的概念后,来看看如何使用Go Client对InfluxDB进行数据基本操作。
初始化客户端
package main
import (
"context"
"fmt"
"time"
"github.com/influxdata/influxdb-client-go/v2"
)
func main() {
// Create a client
// You can generate an API Token from the "API Tokens Tab" in the UI
client := influxdb2.NewClient("http://192.168.153.21:8086", "fKKv_DPSO3qiiHLgn38HeTNRhRPeNMYf2zSJVoMNWIpzoQBJ7Ugmc4He-TMm7dW8Mrbt_wgIKTi2-e-_YAQMgQ==")
// always close client at the end
defer client.Close()
}
通常InfluxDB的服务开在:8086端口,进行连接时需要使用token进行认证。需要注意最后释放客户端的连接。
写数据
这里我们先声明我们所属的organization以及使用的bucket。
bucket := "example-bucket"
org := "example-org"
每一个writeAPI都需要唯一的organization和bucket对来指明。特别的,有两种写API,分别是:
WriteAPI(org, bucket string) api.WriteAPI:异步,非阻塞WriteAPIBlocking(org, bucket string) api.WriteAPIBlocking:同步,阻塞
推荐在有频繁的数据写入时使用异步写,使用异步写的时候有两个要点,一是buffer size,二是flush interval。如果不显式的使用Flush(),那么在数据积累到buffer size或者时间满足flush interval时会将数据进行写入。
以WriteAPIBlocking为例,获取一个写接口。
writeAPI := client.WriteAPIBlocking(org, bucket)
然后进行数据写入:
- 首先创建一个point,然后使用
WritePoint方法预写到数据库中;
p := influxdb2.NewPoint("stat",
map[string]string{"unit": "temperature"},
map[string]interface{}{"avg": 24.5, "max": 45},
time.Now())
writeAPI.WritePoint(context.Background(), p)
这里我们看一下NewPoint对应的函数签名:
func NewPoint(
measurement string,
tags map[string]string,
fields map[string]interface{},
ts time.Time,
) *write.Point {
return write.NewPoint(measurement, tags, fields, ts)
}
刚好对应上前面所涉及的一些概念。再复习一下前面,对于每一个数据点,我们使用series key来标定,而series key包括的内容就是measurement、tag set以及field key。再加上特定的时间戳,我们就能确定唯一的数据point。
除了通过实例化Point写数据,还可以使用InfluxDB Line Protocol去写数据。具体参考InfluxDB Client Go的GitHub文档。
这里Line Protocol是基于文本格式的measurement、tag set、field set以及timestamp的数据组织形式。语法如下:
// Syntax
<measurement>[,<tag_key>=<tag_value>[,<tag_key>=<tag_value>]] <field_key>=<field_value>[,<field_key>=<field_value>] [<timestamp>]
// Example
myMeasurement,tag1=value1,tag2=value2 fieldKey="fieldValue" 1556813561098000000
具体来说有以下元素:
measurementName,tagKey=tagValue fieldKey="fieldValue" 1465839830100400200
--------------- --------------- --------------------- -------------------
| | | |
Measurement Tag set Field set Timestamp
读数据
读数据则使用QueryAPI,利用查询语句进行数据读出。
result, err := queryAPI.Query(context.Background(), `from(bucket:"<bucket>")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "stat")`)
if err == nil {
for result.Next() {
if result.TableChanged() {
fmt.Printf("table: %s\n", result.TableMetadata().String())
}
fmt.Printf("value: %v\n", result.Record().Value())
}
if result.Err() != nil {
fmt.Printf("query parsing error: %s\n", result.Err().Error())
}
} else {
panic(err)
}
参考整理
概念:https://docs.influxdata.com/influxdb/v2.3/reference/key-concepts/
GitHub Go Client:https://github.com/influxdata/influxdb-client-go
官方文档对Go Client的说明:https://docs.influxdata.com/influxdb/v2.3/api-guide/client-libraries/go/
Line Protocol:https://docs.influxdata.com/influxdb/v2.3/reference/syntax/line-protocol/
中文文档(版本较老):https://jasper-zhang1.gitbooks.io/influxdb/content/Concepts/key_concepts.html