来源: NSDI'22
作者:Alibaba Group
摘要
在ML as a Service中,数据中心为ML提供算力保证。而多样的ML工作负载面对异构GPU集群时会出现一些问题。通过两个月的数据收集,采集了超过6000个GPU的生产数据。并发现集群调度面临的一些问题:
- 低GPU利用率
- 长队列延迟
- 需要高端GPU的任务调度难度大
- 异构机器负载不均衡
- CPU潜在的瓶颈问题
文章对上述问题提供了一些解决方案。
本文的最大贡献是提供了一个真实的大规模生产级别的ML集群的追踪数据,并在此基础之上进行分析,为ML as a Service - 云环境下的ML工作负载调度提供了重要的一手数据。
Introduction
在ML框架下的任务需要不同的调度策略,例如GPU局部性、群调度,而且需要调配跨数量级的资源。同时集群中的机器是异构的,一些配置如下图:
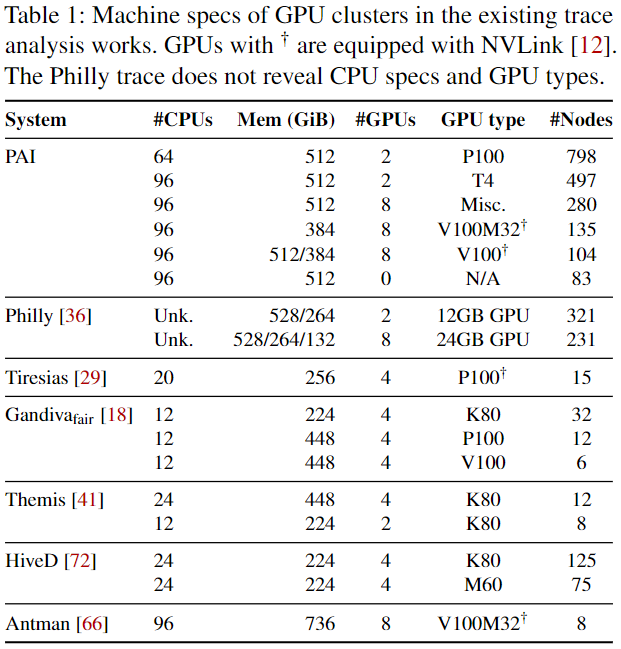
而异构的运行环境给资源管理和调度带来新的困难。
GPU碎片化使用带来的低利用率
例如一个任务实例只使用GPU资源的一部分。流处理程序的GPU利用率的中位数值只有0.042GPU。粗粒度的GPU分配使得资源使用率低下。
为解决这个问题,文章提出了GPU sharing,一种可以以时分复用的方式让多个任务共享GPU的控制方式。使用该方式,将许多低GPU的工作负载整合起来,使用一个GPU,提高资源使用效率。此外,这种共享方式不会引起资源争用干扰,资源竞争的概率十分小。
短任务面临的长排队延迟
短时间运行的任务实例容易由于队列头阻塞而导致长队列延迟,大约9%的任务排队等待的时间超过他们的执行时间。
一种有效的解决方案是预测任务运行时间,并将短任务优先级尽可能提高,避免与长任务竞争。通过仔细的特征工程,我们可以预测大多数重复任务的持续时间,误差在25%以内,这足以根据之前的工作建议做出质量调度决策(因为,通过观察,集群中有65%的任务有重复的工作负载)。跟踪驱动的仿真结果表明,通过预测任务持续时间采用最短作业优先调度,平均完成时间减少63%以上。
高GPU使用的作业难以进行调度
集群中的一些任务要求无共享的使用GPU,以利用高级硬件特性,达到加速训练的目的,如NVLink[12],因此,对这些任务难以进行调度。
集群中的调度器使用一个简单的 reserving-and-packing 策略在集群中分辨出这样的任务。它保留高端的GPU机器,如,V100 with NVLinks,用于少数具有挑剔调度要求的高GPU任务,同时将其他工作负载打包到不太高级的机器上,使用GPU共享策略保证资源的利用率。此外,该策略还提升了平均队列等待延迟,加快了任务调度。
负载不均衡
明显的是,低端GPU比高端GPU更加拥挤,前者被分配了70%的GPU和CPU资源,而后者只被分配35%的CPU和49%的GPU资源。
工作负载和机器之间也存在供应不匹配的问题。例如,工作在8GPU的工作负载对CPU的需求是那些可以提供12GPU的1.9倍,简而言之就是,那些性能更弱的机器被分配了与其能力不匹配的工作负载。
CPU瓶颈
一些机器学习、深度学习作业不仅仅需要GPU,有的也需要CPU资源,这造成CPU瓶颈。同时发现, 工作在高CPU利用率机器上的任务容易减速。
工作负载特征分析
追踪概述
关于数据集的数据内容和下载请查看clusterdata。实际上并不能明确的知道容器里执行的到底是什么类型的训练任务,但是可以从作业名中得到一些线索。
下图为PAI和Trace的架构:
Jobs, tasks, and instances
用户提交jobs,一个job有一个或多个tasks来扮演不同的计算角色,每个task使用Docker运行一个或多个instances。
例如,一个分布式训练job有一个参数服务task,该task有两个实例,此外还有一个worker task有10个实例。一个task的所有instances有相同的资源需求,并且需要gang-schedule。
我们主要关注任务实例,也就是instance这一级别的工作。
Heavy-skewed instance distribution
PAI追踪了120万个tasks,超过750万个instances,由超过1300个用户提交。下图展示了用户提交的task instance的分布,表现出严重的不平衡:
5%的用户提交了大概77%的task instances,大概每个用户运行1.75万instance。而50%的用户每人运行少于180个instances。
The prevalence of gang-scheduling
分布式的任务需要gang-schedule(认为超过2个GPU的调度),如下图:
大约85%的任务需要这样的需求,有20%的任务需要超过100个GPU的调度,还有的甚至要进行超过1000个GPU的调度。
GPU locality
除了gang-schedule,一个任务可能会在同一台机器上的多个GPU上运行它的所有实例,也就是存在GPU局部性。
虽然这种情况会引发调度延迟的加剧(一些任务等待调度的时间延长),但是在单节点的GPU上进行训练减少了GPU to GPU的通信时间。
但是通过增强GPU局部性,可以让某些任务的训练速度加快10倍。
GPU sharing
GPU sharing利用时分复用的原理使得多用户可共享一个GPU进行训练。
Various GPU types to choose from
PAI提供异构的GPU可供任务选择。在集群中只有6%的训练任务需要运行在特定的GPU上,其他的任务则对GPU类型没有限制。
时间模型
从时间角度来观察PAI工作负载。
Diurnal task submissions and resource requests
下图是一周中task和instance的提交情况,还有总体的资源请求情况:
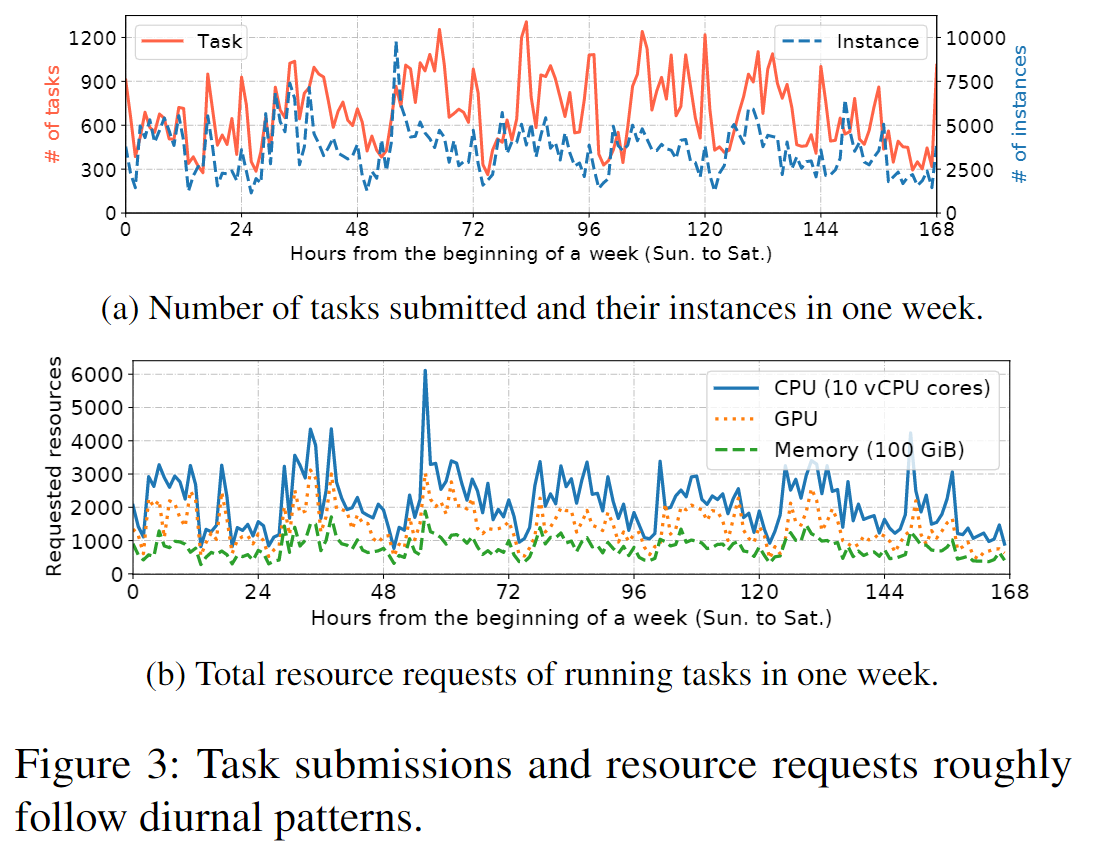
从中可以得到以下几点信息:
- 周中提交数量多余周末
- 夜晚也有任务提交的高峰
- 大多数在夜间提交的任务并非计算密集型
Instance run-time in a wide range
下图展示了instance运行时间的分布:
- 运行时间的变化范围很大,有4个数量级
Non-uniform queueing delays
理解为在队列中等待调度的时间。这段时间指task提交到instance执行的时间,如下图:
- 对比long-task,short-task通常花费更多比例的时间在等待调度上
- 大约9%的短作业实例花费超过完成时间的一半去等待调度,而长左右这个数值只有3%
此外,task instance的队列延迟还取决于GPU的需求,如下图:
- 那些可以共享GPU的instance(GPU需求为0-1)可以更快的被调度,其等待调度的等待时间P90值为497s
- 而不支持共享GPU的任务的这一值为1150
同时,长队列等待时间也出现在一些需要高端GPU的任务中,如下图:
- 例如在V100和V100M32上的instance需要更多等待时间
空间模型
通过分析资源请求和使用,分析了PAI task instance的空间模型。每15s进行一次测量,并使用虚拟化工具[2, 25]去分析用户的负载模式和他们的资源需求。
Heavy-tailed distribution of resource requests
如下图:
-
图5(a)(b)(c)中的蓝色实现表示,大约20%的实例占用了80%的资源,而其余的只要很少一部分资源
-
以P95和中位数比较,P95需要12vCPU、1GPU、59GB内存,而中位数只要6vCPU、0.5GPU和29GB内存。
Uneven resource usage: Low on GPU but high on CPU
集群中instance的资源使用中位数在1.4vCPU、0.042GPU和3.5GB内存,远小于资源请求的中位数。
-
观察到存在GPU空闲和CPU不够用的情况,并推断GPU的低利用率不是因为对GPU的需求少,而是CPU瓶颈限制了GPU的使用
-
从5(b)中也可以看到,对GPU的实际使用远小于GPU资源的需求
-
从5(d)中,对应X坐标>1的值表示CPU的使用量大于申请的量,有19%的instance出现这种情况,而超量使用GPU的只有约3%的实例,对内存来说这一值也只有9%
GPU利用率
计算资源利用率
包括CPU、GPU和Memory。监控系统每15s收集数据,并存到时间序列数据库中。
如下图:
- 相比内存来说,GPU和CPU利用率普遍高,也说明大部分任务不是内存集中型
- GPU利用率的P90跨度很广,这与GPU使用有突发性相关,同时也与调度策略有关
网络和I/O的低利用率
- 网络中数据接收量普遍较低
- 网络带宽普遍不能达到指定数值(如不能达到保证的10Gbps、32Gbps)
- iowait模式比usr和kernel模式少三个数量级,这意味着CPU大多数时间在进行计算而不是在等待I/O
优化集群管理的方向
在PAI中,集群管理有两个优化目标:
- 实现GPU的高利用率
- 缩短task的运行时间
GPU共享
与CPU不同,GPU天生就没有共享特性。PAI以时分复用和空分复用(内存)方式,使多个任务实例可以共享一个GPU。
Benefits of GPU sharing
下图将是否使用GPU sharing的表现进行对比:
- 平均而言,共享只需要50%的GPU资源,可节省高达73%的费用,节省大量的GPU资源
Does GPU sharing cause contention?
随着利用率的增加,运行在共享GPU上的实例开始争夺资源。
- 由于大多数高利用率的GPU上面运行单个实例(平均4.5%的GPU运行多个实例),因此不会发生争用,所以认为GPU共享不会在集群中引起严重的争用
预测重复任务的持续时间
文章认为预测ML认为实例的运行时间是实现更好调度的关键。现存的预测方案基于迭代次数、损耗曲线、目标精度和训练速度等指标。
The prevalence of recurring tasks
文章发现大多数任务都是重复的,并且它们的实例运行时可以很好地从过去的执行中预测出来。通过对任务的元数据,如:脚本、命令行参数、数据源和输出,进行hash得到Group tag来标识重复的任务。
- 约65%的任务在trace中至少运行5轮
- 大多数重复任务每个周期都有相似的运行时间
Instance duration prediction for recurring tasks
实际的预测使用三个特征作为输入:
- task’s username - User
- resource request - Resource including GPU and other resources
- group tag - Group
利用上述特征,基于CART(Classification And Regression Tress)算法预测实例的平均运行时间。作为评估,使用至少重复5轮的任务,下图为预测详情:
从上图得知:
- Group是重要指标
Benefits for scheduling
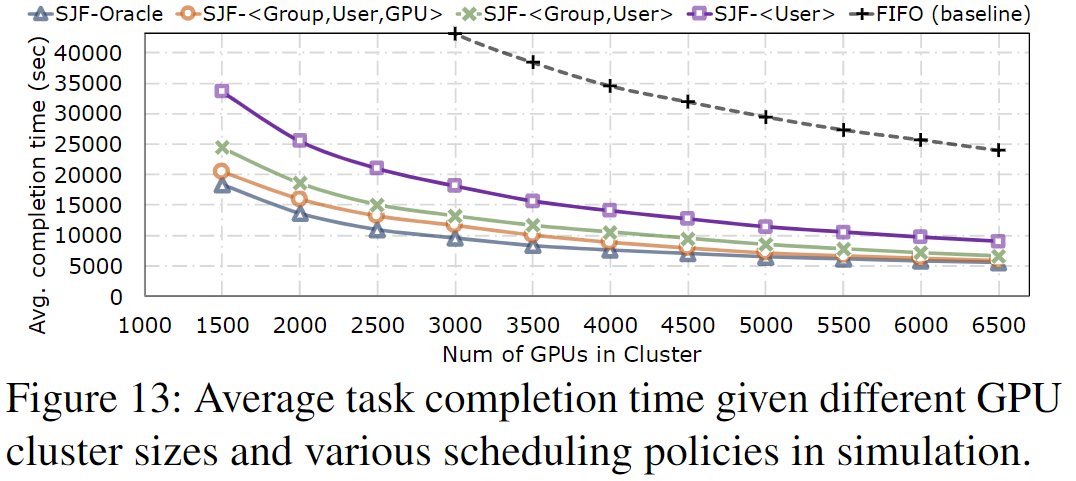
上图展示不同调度方法。
- SJF-Oracle明显好于其他算法,该算法基于真实的任务持续时间和预测算法
- 给的特征越多,效果越好
调度面临的挑战
本部分使用两个案例:典型的ML tasks,分别有高/低GPU资源需求的特性。
高GPU需求任务的研究
集群中一些任务有计算密集型实例,需要很高的GPU资源。
NLP with advanced language models
NLP任务中,73%的有大规模的输入,需要16GB或更高的内存。下图展示了NLP实例对GPU资源的需求和使用情况:
- 约40%的实例需要超过1个GPU,超过那些常规的任务
Image classification with massive output
集群中还有些任务需要GPU to GPU的高效率通信,GPU局部性可以提高通信效率。典型代表就是图像分类模型,其中存在规模庞大的全连接层,要求在工作实例之间进行大量的梯度更新,需要使用大量的通信资源,使通信成为瓶颈。
如图14(b)中,启用NVLink极大缩短了任务的运行时间。
低GPU需求的任务研究
使用三种广泛使用的任务进行研究。一些CPU密集型的任务可能会导致GPU的利用率低下。
CTR prediction model training and inference
在追踪中,有6.7%的广告点击率预测系统( advertisement click- through rate (CTR) prediction)使用了CTR模型。其中有25%的实例负责训练,75%的实例负责推理工作。这些实例的CPU和GPU资源分布如下:
- 与训练相比,执行推理任务的实例具有更高的CPU利用率,因为它们处理源源不断到达的大量数据
- 有近75%的实例使用的GPU小于0.1
下图展示了这些模型运行时资源情况:
- CPU资源的使用明显高于其他资源
GNN training
图神经网络也是计算密集型任务, CPU的使用率远超GPU,如下图所示:
- 在模型训练阶段,需要进行大量的CPU操作
Reinforcement learning
加强学习算法通过并行模拟迭代生成一批数据将生成的数据放到GPU上进行训练,以改进学习策略。
- 有72%的任务需要超过10个实例来完成,加大调度难度
- 但是大多数RL任务对GPU的需求极低
部署调度策略
Reserving-and-packing
集群中有意保留高端GPU资源,而尽可能将任务打包在一起,共享使用低端GPU资源。
对于每个任务,调度程序生成一个有序的分配计划序列;每个计划指定了预期的GPU设备,并与尝试超时值相关联。
对于需要高端GPU的任务,先尝试高端GPU的分配,然后再尝试较低端GPU的分配;对于其他任务,顺序颠倒过来,GPU调度器是在基于局部树的调度系统Fuxi[26,71]上实现的。
Load-balancing
在Reserving-and-packing的前提下,调度器还会优先将实例调度到分配率较低的机器上,分配率衡量为已分配的CPU、内存和GPU的加权总和,这些资源按机器的容量进行标准化。
Benefits
具体对应两种调度方法:
- 简单地使用渐进式填充的负载平衡机器(总是将任务的实例调度到利用率最低的节点)
- 不考虑负载均衡,只执行Reserving-and-packing
下图展示了这两种策略的实际表现:
-
请注意,任务的排队延迟也包括在它的组调度实例的排队延迟
-
在这两个策略下,超过90%的实例和任务会立即启动
-
与负载均衡算法相比,Reserving-and-packing算法将平均任务排队率降低了45%,主要原因是尾部延迟的显著缩短超过10000秒
-
进一步比较了业务关键型任务和请求V100的实例的排队延迟,在两种策略下,GPU的平均任务排队延迟减少了68%
其他待解决的问题
Mismatch between machine specs and instance requests
该问题带来的影响如下图:
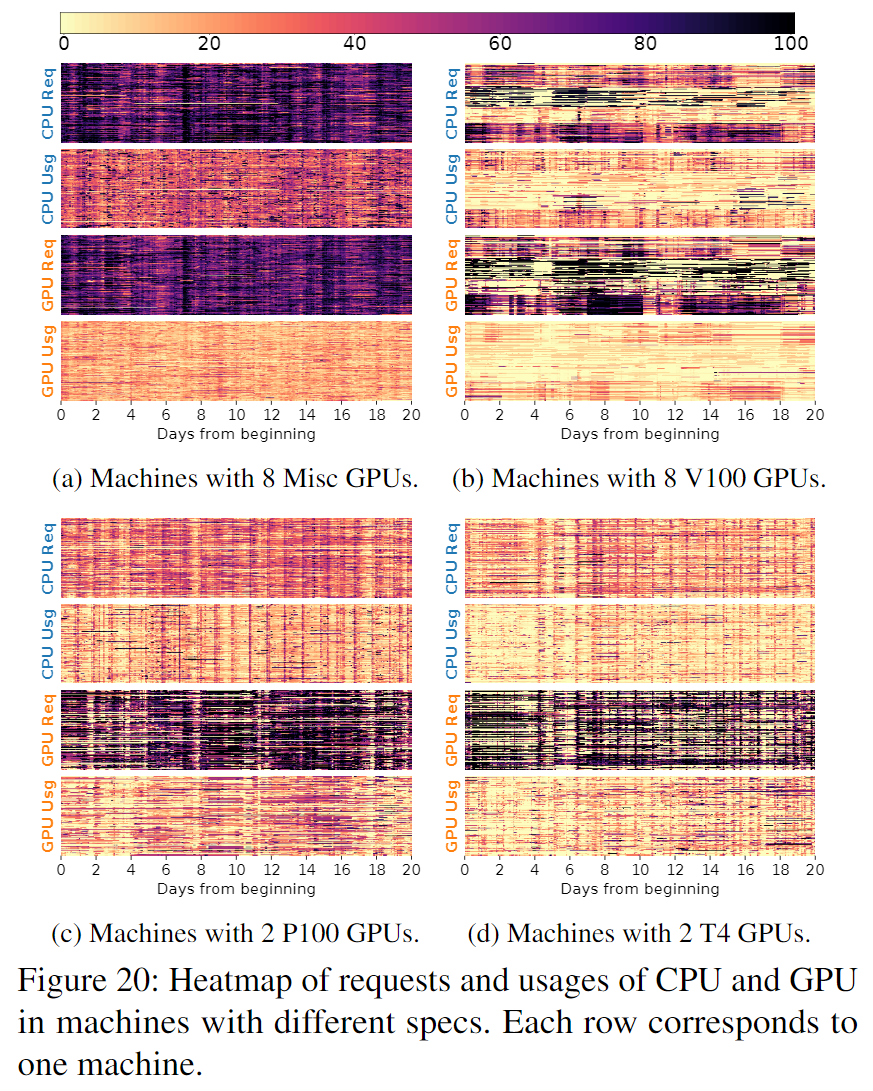
- 这直接导致:相较于高端机器来说,低端机器明显更拥挤,它们的资源使用率也高于高端机器