来源:IEEE CLOUD'21
作者:IBM
⭐摘要
问题背景
微服务内部通信的复杂性,必须考虑资源利用、调度策略和请求均衡之间的平衡,以防止跨微服务级联的服务质量下降。
文章做了什么
提出资源管理系统RunWild,可以控制所有节点涉及到的微服务管理:
- 扩缩容
- 调度
- 自动的根据指定性能表现的负载和性能平衡优化
- 统一的持续部署方案
着重强调了协同metrics感知在预测资源使用和制定部署计划中的重要性。
在IBM云进行实验,以K8s的自动调度为基线,减少P90响应时间11%,增加10%的吞吐率,降低30%的资源使用。
贡献
- 扩展的部署框架:适用于K8s的调度框架,用来在资源分配、部署、和运行时来控制部署机制;
- 通用的建模方法:综合考虑微服务特性、节点的相对独立性、工作负载和全局协同节点状态感知,通过结合聚类和回归技术预测资源使用;
- 微服务间交互指标:一个称为内聚的指标反映了在同一个节点上放置高度相互通信的微服务的优势;
- 通过Service Mesh对运行时工作负载进行分区:利用服务网格操作流量路由,用其控制能力来划分工作负载以匹配资源的分配。
⭐现有技术存在的问题
水平伸缩
- 超过某个阈值时,实例的增多与性能表现的增长不匹配,正如收益递减定律所解释的那样;
- 资源过度分配并不会显著增加性能表现;
- 而资源不足会导致性能下降或者致命错误。
垂直伸缩
- K8s虽然可以支持HPA和VPA,但是不能一起工作,同时进行HPA和VPA难免会造成干扰。
此外,复杂的资源依赖,全局的资源调度策略使得伸缩方案受多方面影响。
文章的动机是识别、描述和管理所有因素和维度,以实现统一的部署解决方案,而不是运行相互干扰的机制。
部署的三个角度
- 所部署的服务的实例副本数;
- 节点上每个实例所得到的资源;
- 每个实例的网络容量。
然后引出下面4个重要的问题:
- 调度所涉及到的策略、资源和具体情景很复杂,要考虑的东西太多;
- 同一节点上部署的服务可能对资源的争用很敏感;
- 微服务之间的通信,亲和性等因素会影响到全局的服务性能表现、响应事件及吞吐量,最好的方式是使部署的微服务减少跨节点的通信;
- 如何将请求负载均衡到不同实例以带来更好的网络表现,虽然Service Mesh能够实现负载的分发,但是难以解决上述问题。
文章列举了一些其他文章做的工作,并对比这些工作解决了上述4个问题中的哪些:
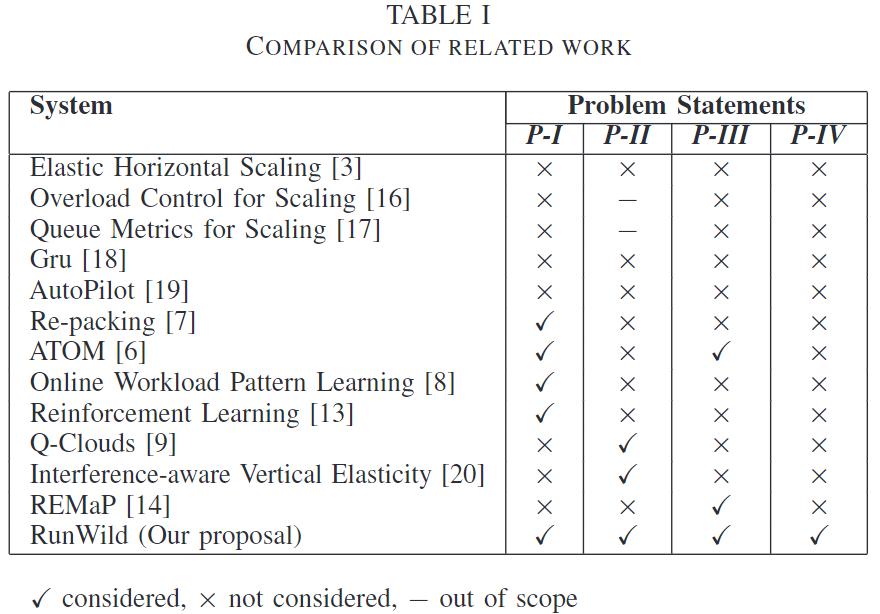
⭐RunWild
RunWild主要解决:决定实例数量,决定在哪个节点放置实例,如何对工作负载进行分区,如何根据众多资源类型和情景优化部署?
涉及到的技术有:
- 用循环执行的监控-分析系统对部署进行分析:根据监控和分析环节,设计一个资源使用模型,来预测资源使用。利用automated AI技术获得优化的回归模型来预测资源使用,同时考虑消息请求和节点上资源竞争产生的扰动因素。
- 根据分析制定部署计划:定义一个聚合指标,表示微服务间(通信)的联系程度。部署计划应用于所有机器,包括水平部署、资源分配、放置调度和负载均衡。
- 执行部署:利用Service Mesh提供的运行时链路控制,通过标签动态将工作负载进行分区。
系统架构
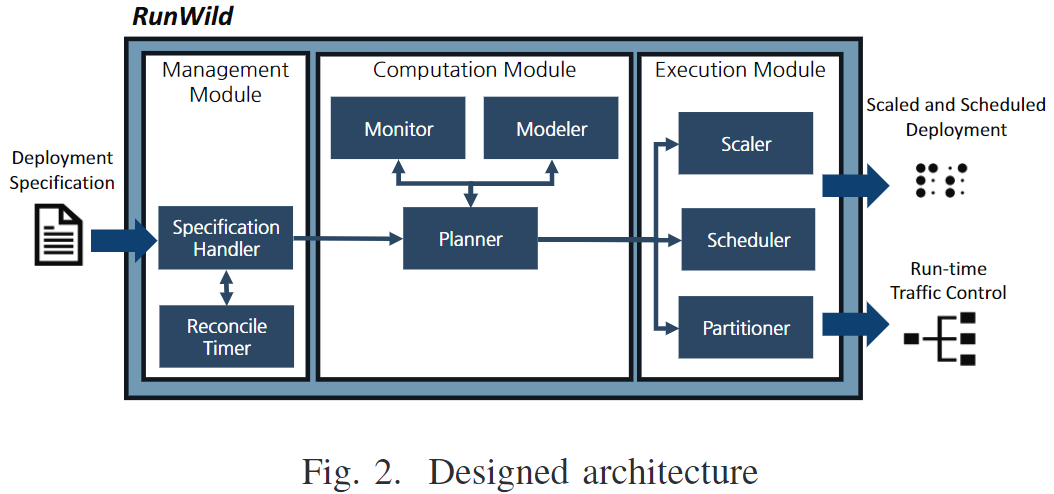
Management Module
接收用户提交的部署细节信息。
- Specification Handler:管理输入的部署文件并自动化处理;
- Reconcile Timer:计算并触发每个输入规范的部署自动化过程。
Computation Module
在全周期中给出部署的解决方案。
- Monitor:监控每个实例的资源使用情况和工作负载,文章将工作负载理解为请求的数量;
- Modeler:用来预测资源使用的模型;
- Planner:计算部署计划,包括实例数量、节点放置策略、资源预留、工作负载分区。
Execution Module
用来执行计算的部署结果。
- Scaler:更新实例数量;
- Scheduler:将容器放置到计划的节点;
- Partitioner:配置链路控制机制,对工作负载进行计划的分区。
系统实现
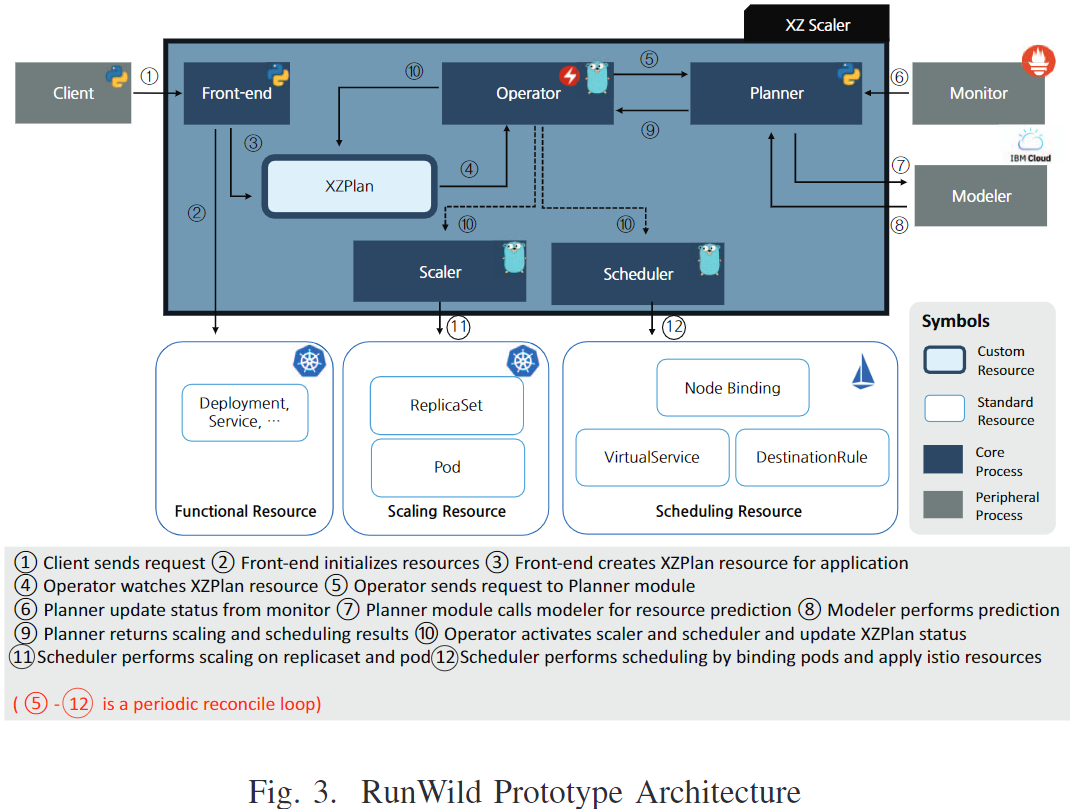
⭐实验测试
集群包含8个节点,每个节点4vCPU,16GB内存,并部署了Istio和Prometheus。
部署70个微服务,600个容器实例,收集了3天的数据。