来源:ACM SoCC'21
摘要——为什么需要服务级别的故障注入测试
由于微服务架构的特点,负责每个模块的工程师只需专注自己的部分而不需要过多关注整个应用系统。这些应用程序的开发人员不一定都是分布式系统工程师,因此无法预计系统出现部分故障:一旦部署到生产环境中,他们的服务会面临一个或多个依赖项不可用的问题。
作者提出了一种称为服务级故障注入测试的方法和一种称为 Filibuster 的原型实现,可用于在微服务应用程序开发的早期系统地识别弹性问题。
Filibuster 将静态分析和 concolic-style 执行与一种新颖的动态缩减算法相结合,以扩展现有的功能测试套件,以最少的开发人员工作量覆盖故障场景。
并使用 4 个真实工业微服务应用程序的语料库来进行实验。
贡献
- 一种测试微服务应用程序弹性的方法:服务级故障注入测试 (SFIT) 结合了静态分析和 concolic 测试,以探索微服务之间所有可能的故障,从现有的通过功能测试套件开始。
- 一种新颖的动态缩减算法: SFIT 使用一种算法,通过利用将应用程序分解为独立的微服务来减少搜索空间的组合爆炸。
- 实现了SFIT的原型Filibuster:这个基于 Python 的工具可用于测试与 HTTP 通信的服务。我们的原型允许在本地测试服务的弹性,并证明它可以在 Amazon CodeBuild CI/CD 环境中运行,以便在问题进入生产之前检测它们。
- 用 Python 实现的微服务应用程序和错误的语料库:该语料库包含 8 个小型微服务应用程序,每个应用程序都展示了微服务应用程序中使用的单一模式;和 4 个从公开会议演讲中重新实现的行业示例:Audible、Expedia、Mailchimp 和 Netflix。
- 在该语料库上对Filibuster进行评价:证明 Filibuster 可用于识别语料库中的所有错误。我们展示了通过动态缩减可能进行的优化,并提供了有关如何最好地设计微服务应用程序以实现可测试性的见解。
难点
缺乏开源微服务工业应用程序及其相关的错误报告(这两个主要的语料库通常有助于软件测试领域的研究),回答这些错误是否可以在开发过程的早期检测到的问题并不简单。
最终作者构建了4个案例语料库。
-
Audible:一家提供有声读物流媒体移动应用程序的公司。在他们的演示文稿中,他们描述了一个错误,即应用程序服务器在从 Amazon S3 读取数据时不会收到 NotFound 错误。此错误在代码中未处理,并通过一般错误消息传播回移动客户端。他们使用混沌工程发现了这个错误。
-
Expedia:一家提供旅行预订的公司。他们讨论了使用混沌工程来验证如果他们的应用程序服务器尝试从基于相关性对它们进行排序的服务中检索酒店评论,并且该服务不可用,他们将回退到另一个提供按时间排序的评论。
-
Mailchimp:一款用于电子邮件通讯管理的产品。在他们的演示中,他们讨论了两个错误。
- 遗留代码无法处理其数据库服务器返回的指示其为只读情况的错误代码。
- 一项服务变得不可用并将未处理的错误返回给应用程序。
-
Netflix:讨论了他们使用混沌工程基础设施发现的几个错误。
- 错误配置的超时,某个服务调用不正确配置,导致请求花费比预期更长的时间,但保持在超时间隔内。
- 服务配置了回退指向错误的服务。
- 关键的为服务没有配置回退。
架构概述
SFIT 采用开发人员优先的方法,尽早将故障注入测试集成到开发过程中,而无需开发人员使用特定的规范语言编写规范。
SFIT 建立在开发微服务应用程序的以下三个关键点上。
- 微服务独立开发:由于微服务之间可以通过约定的API进行通信,负责其他模块的个别团队成员通常不能很好地理解超出其控制范围的服务的状态或内部结构,无法编写应用程序的详细规范以使用模型检查器自动验证它。
- Mock测试可以防止问题出现:虽然编写模拟测试可以查出一些问题,但是由于这费时费力,对开发来说效益太少,所以开发人员很少进行测试。
- 功能测试的重要性:开发人员编写多个验证应用程序行为的端到端功能测试,而不是编写规范。任何成功的故障注入方法都应该从功能测试开始。
SFIT的实现思路
基于上述三个关键点及下面的两个简单假设:
- 服务通过HTTP进行通信。
- 一个单一的功能测试可以实现所有应用程序行为。
测试流程概述
- 假设从一个通过的功能测试开始,该测试由开发人员编写,在一些未失败的场景下执行应用程序,并验证一些应用程序行为。我们假设通过测试已经排除了逻辑错误。
- 在该测试点注入故障。如果请求出现多种错误,则为每一个错误安排一次测试。这些后续执行被放置在堆栈上,并递归地应用该策略,直到所有路径都被探索。这种算法的灵感来自于DART的concolic测试算法[28]。
- 以Audible App的例子来说,第一个请求发现内容分发服务出现了Timeout or ConnectionError。然后我们向堆栈中追加两次测试执行。
- 接着对内容分发服务进行堆栈中的测试,如果测试中暴露出新的问题,就可以寻找新的错误路径,内容交付引擎的故障可能会导致另一条路径暴露给日志服务。我们继续探索,直到所有的道路都被充分探索。(如:内容交付引擎的故障可能是由于日志服务暴露出的问题,因此搜索到日志服务路径。
在本例中,多个服务具有相互依赖关系;例如,音频下载服务与所有权服务、激活服务和统计服务对话。在这种情况下,我们必须安排覆盖整个失败空间的执行——每个服务可能独立失败的所有方式,以及由于微服务相互影响而导致失败的所有组合。在第4节中,我们将讨论如何减少冗余的路径搜索。
此外,在进行故障注入测试时,需要根据故障情况调整功能测试。为此作者开发了帮助组件使得开发者可以编写条件断言来判断错误的出现。还提供了一个机制来重现错误。
故障注入
该注入方法可以对远程调用继续注入,并通过远程库改变响应。例如一些HTTP、gRPC的库。故障注入的设计思路如下:
- 不返回远程服务的实际响应
- 基于注入的故障返回故障响应(通过修改远程服务响应)
故障识别
故障识别主要包含识别具体的故障和识别故障发生于哪一个微服务。
注入的故障类型都源自于微服务可能发生的故障类型。通常有以下两种错误:
- 服务调用端故障。如Python的request库在发出请求时会有23中意外情况。可以通过指定包含异常的模块或者配置中手动指定这些问题,依此识别故障。这里作者将该类请求中的Timeout和ConnectionError作为主要考虑的错误类型。
- 被调用端故障。被调用的服务也可能返回一个错误响应。例如一个服务依赖的另一个微服务抛出了Timeout,那这个服务就可能返回500。作者通过对程序源码使用静态分析技术对类似的响应进行识别。例如在Flask框架中查找return或raise语句。
但还存在一个问题:在使用HTTP做请求时,请求的URL并不能作为识别服务本体的标识。为解决这个问题,使用额外的工具记录调用的服务。该工具放置在接收服务请求的Web框架上,因此可以在被调用之前记录被调用者的服务信息。在获取该被调用者的信息后,将信息传给中台,以便进行后续的测试。
注入故障后对功能的调整
开发者需要根据故障注入的结果去调整功能,修复没有考虑到的问题。作者提供了一个帮助模块去编写故障断言,例如:
if a fault was injected on Service A {
...
}
对系统行为在失败的情况下进行捕获和处理。开发人员应将这些条件断言添加到现有的功能测试中。
一个典型的流程如下:
- 开发者进行功能测试并通过。
- 注入故障
- 原有的功能测试因为故障的注入出现问题
- 开发者通过提供的帮助工具,可以对新出现的故障进行断言,从而捕获因故障注入出现的故障。例如:Audible会报出
if a fault was injected on the stats ser- vice, the service should still play the audiobook.。基于此,开发者可以使用反例来重现先前的测试,以证明这些断言。
故障搜索路径动态缩减
为了识别尽可能多的错误,必须理想地探索服务失败的组合。为了实现故障空间的最大覆盖所需的测试执行次数是非常多的。
但是,可将应用分解成多个独立的微服务来显著减少搜索空间并且保证完整性。以下图为例:
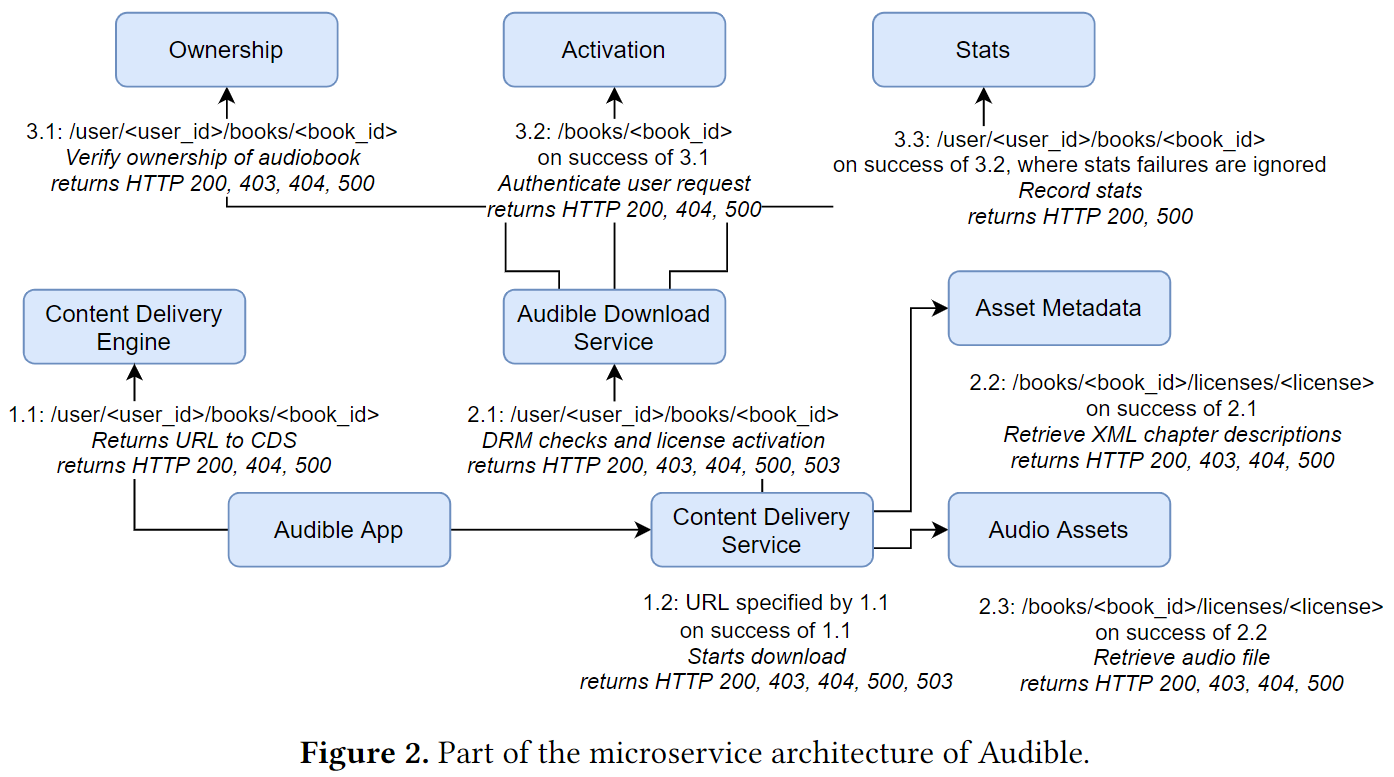
对于ADS服务
- 先只考虑服务子集的故障,如ADS下载服务和CDS内容分发服务以及他们的依赖项。
- 对于ADS可能产生的故障,需要考虑三种依赖类别:
- Ownership:验证某个用户是否拥有某本书的所有权;
- Activation:验证用户的请求;
- Stats:对本次事件改变的状态进行记录;
- 如果上面三个依赖服务中的任何一个出现失败,那么ADS服务就会返回错误。但需要注意,Stats的失败不会影响这次请求的结果(因为“where stats failures are ignored”)。
- 因此,Ownership和Activation的失败会导致ADS返回500,但Stats的失败不会影响ADS,如果Ownership和Activation成功而Stats失败,ADS仍返回200。
对于CDS服务
- CDS服务依赖的微服务子集是Asset Metadata和Audio Assets,我们需要考虑这两个服务会发生的故障以及他们组合起来会发生的故障。
- 但是,由于ADS的请求URL
/user/<uesr_id>/books/<book_id>与Stats的URL相同,又因为CDS服务依赖于ADS服务,所以也应当将Stats服务考虑进去。 - 所以实际包含的CDS子服务应是:Asset Metadata+Audio Asset+Stats。
三条准则
- 充分考虑服务依赖项的所有失败方式,让我们知道每个服务和多个依赖服务失败时会发生什么行为,返回什么结果。
- 我们需要明确将故障注入后会对服务产生什么样的影响,并依据此简化注入。例如我们已经知道CDS的某个依赖项在发生错误时会返回500,那么就可以直接在CDS中注入500错误响应。
- 如果已经在服务中注入了故障,那么就不用进行测试了,因为已经观察到了程序的行为。
动态缩减算法
该算法将测试的搜索空间指数级缩小,基本思路是:
- 缩减前:数量级是服务请求总数
- 缩减后:数量级变成给定服务最大能发出的请求数
具体来说如图2:
- 缩减前:最大有8条边需要处理,整个应用有8个请求路径
- 缩减后:最大仅需要处理3条边,因为ADS是依赖项最多的服务,有3个请求发送路径
另外依据的一个前提是,微服务调用链拓扑结构上深度优先比广度优先更为明显。
原型实现:Filibuster
使用Python及相关的开源组件,如使用opentelemetry来实现请求链路追踪、识别服务依赖关系。
组件功能
系统的组件可以实现服务请求识别、服务依赖关系分析,并于Filibuster通信。服务器负责在本地进程、Docker Compose 或 Kubernetes 中启动与应用程序关联的所有服务。运行功能测试、记录和维护要执行的测试执行堆栈、执行功能测试断言、报告测试失败并聚合测试覆盖率。服务器提供了一个 API,功能测试可以使用该 API 来编写条件断言,并使用反例文件允许测试重放。测试覆盖率由服务器从每个单独的服务中聚合而成。
静态分析
Filibuster需要进行静态分析,以识别每个服务可以返回的错误类型。作者使用词法分析技术,遍历源代码的抽象语法树来识别错误。Flask中的raise语句可以被分析道,然后捕获这些语句要发送的HTTP错误响应及状态码。
注入故障
Filibuster可以注入下面类型的故障;
- 调用端异常:这些异常由request库抛出,如指示
Timeout的等错误。 - 响应异常:来自被调用端返回异常。
应用语料库
一个包含8种变体示例的电影订票程序,每个示例都展示了微服务应用程序中观察到的特定模式。还有 4 个行业示例:Audible、Expedia、Mailchimp 和 Netflix。
每个示例都包含单元测试以及验证应用程序功能行为的功能测试。这些示例可以在Docker或K8s环境中运行。
电影院订票应用示例
该应用由4个微服务组成:
- Showtimes: returns the show times for movies;
- Movies: returns information for a given movie;
- Bookings: given a username, returns information about the bookings for that user;
- Users: 存储用户信息并处理用户订票请求,并在过程中为用户展示电影信息。
它的另外7个变体有:
- bookings talks directly to the movies;
- same as 1, but the users service has a retry loop around its calls to the bookings service;
- same as 1, but each service talks to an external service before issuing any requests, the users service makes a request to IMDB, the bookings service makes a request to Fandango, the movies service makes a request to Rotten Tomatoes;
- all requests happen regardless of failure; in the event of failure, a hardcoded, default, response is used;
- adds a second replica of bookings, that is contacted in the event of failure of the primary replica;
- same as 5, but the users service makes a call to a health check endpoint on the primary bookings replica before issuing the actual request;
- example is collapsed into monolith(单体结构) where an API server makes requests to the it with a retry loop.
工业级应用
Audible
架构如上图2所示。包含如下服务:
- Content Delivery Service (CDS):
- IN: book_id 和 user_id
- OUT:(在验证之后) 音频内容和元数据
- Content Delivery Engine (CDE):
- IN: book_id 和 user_id
- OUT:相关CDS的URL
- Audible App:模拟移动应用
- 首先向CDE请求获得内容的URL
- 再根据URL请求CDS
- Audible Download Service: 鉴权、授权并记录日志
- IN: book_id 和 user_id
- OUT:权限鉴别结果
- Ownership: 验证读者对图书的所有权
- IN:book_id 和 user_id
- OUT:鉴权结果
- Activation:为用户激活DRM许可证
- IN:book_id
- OUT:DRM Access
- Stats:记录读者和图书许可的信息
- IN:book_id 和 user_id
- OUT:记录结果
- Asset Metadata:存储音频元数据,如章节信息
- IN:book_id 和 license
- OUT:检索到的音频XML信息
- Audio Assets:提供音频存储服务
- IN:book_id 和 license
- OUT:检索到的音频文件
作者在实际部署上进行了一些调整:
- Asset Metadata和Audio Assets是 AWS S3 存储桶。为了模拟这一点创建 HTTP 服务,如果可用,则返回包含资产的 200 OK,如果资产不存在,则返回 404 Not Found。
- Ownership和Activation是 AWS RDS 实例。为了模拟这一点创建了实现 REST 模式的 HTTP 服务:如果用户不拥有该书,则返回 403 Forbidden,如果该书不存在,则返回 404 Not Found,否则返回 200 OK。
- Stats 服务是一个 AWS DynamoDB 实例。为了模拟这一点,我们创建了一个返回 200 OK 的 HTTP 服务。
对于功能测试的尝试是为用户下载有声读物的测试。如果缺少图书的章节信息,Asset Metadata可以返回 404 Not Found 响应:这是 Audible 演示中讨论的错误,会导致在移动应用程序中向用户显示一般错误。
Expedia
包含如下三个微服务:
- Review ML:按相关性顺序返回评论
- Review Time:按时间顺序返回评论
- API Gateway:根据服务可用性,从 Review ML 或 Review Time 将评论返回给用户
Mailchimp
包含五个微服务:
- Requestmapper:将电子邮件活动中的 URL 映射到实际资源
- DB Primary:数据库的主要副本
- DB Secondary:数据库次要副本
- App Server:向 Requestmapper 服务发出请求以解析 URL,然后对数据库执行读后写请求,并在主数据库不可用的情况下回退到辅助数据库副本
- Load Balancer:对请求进行负载均衡
同样的,在实际部署时做出一些调整:
- DB Primary 和 Secondary 服务是 MySQL 实例。为了模拟这一点创建一个 HTTP 服务,该服务要么在成功读取或写入时返回 200 OK,要么在数据库为只读时返回 403 Forbidden。
- 负载均衡器服务是一个 HAProxy 实例。为了模拟这一点创建一个 HTTP 代理做负载均衡。
故障信息有两个:
- MySQL instance is read-only:当 MySQL 实例为只读时,数据库会返回一个在代码的一个区域中未处理的错误。由于 Mailchimp 使用 PHP,这个错误会直接呈现到页面的输出中,我们通过将 403 Forbidden 响应转换为直接插入页面的输出来模拟这一点。
- Requestmapper is unavailable:当 Requestmapper 服务不可用时,App Server 无法正确处理错误,向负载均衡器返回 500 Internal Server Error。但是,负载均衡器仅配置为通过返回格式化的错误页面来处理 503 Service Unavailable 错误。
Netflix
包含十个微服务。
- Client:模拟移动客户端
- API Gateway:展示用户主页
- User Profile:返回用户信息
- Bookmarks:返回最后查看的位置
- My List:返回用户的电影列表
- User Recs.:返回用户推荐的电影
- Ratings:返回用户的评分
- Telemetry: 记录日志信息
- Trending:返回电影观看趋势
- Global Recs.:返回推荐电影
对于功能测试,我们有一个尝试为用户加载 Netflix 主页的功能测试。
故障信息有三个:
- Misconfigured timeouts:User Profile服务以 10 秒的超时时间调用日志服务;但是,API Gateway会以 1 秒的超时时间调用用户配置文件服务。
- Fallbacks to the same server:如果我My List服务不可用,系统将重试。
- Critical services with no fallbacks:User Profile服务没配置回退。
实验评估
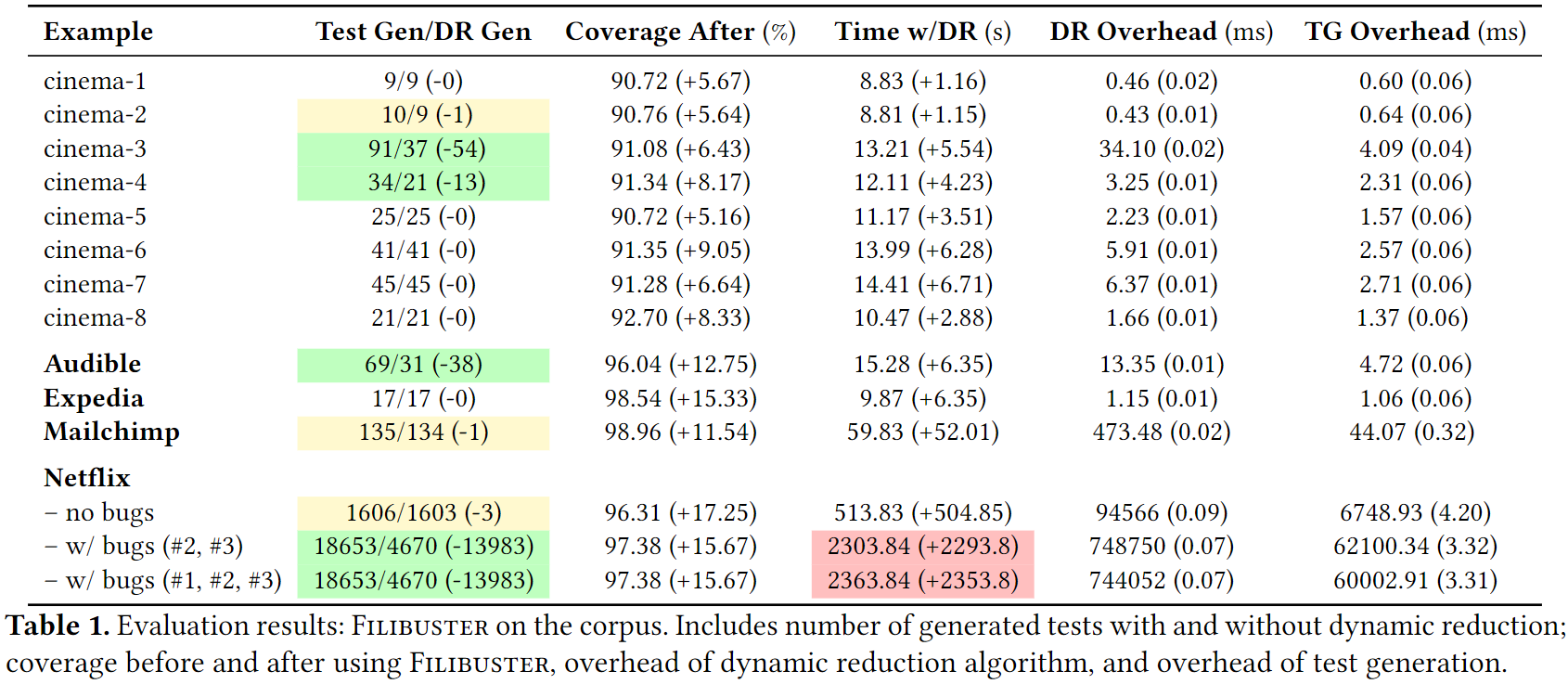
在具有 15 GB 内存和 8 个 vCPU 的 AWS CodeBuild 实例上运行了所有示例。在 Filibuster 运行开始时,启动了每个示例的所有服务,等待这些服务上线并在测试结束时终止它们,不会在测试执行之间重新启动服务。
Tests Generated and Increased Coverage
-
Test Gen/DR Gen:表示 Filibuster 生成和执行的测试数量。由于每个示例只有一个功能测试,因此这些数字包括该测试的总数,因为 Filibuster 必须首先执行初始通过的功能测试,以确定在哪里注入故障。在语料库中包含错误的所有示例中,可以使用Filibuster 识别错误。
-
Coverage After:表示报表覆盖率的增加。通过生成涵盖可能故障的测试,我们能够增加应用程序的覆盖率。这些数字仅用于功能测试。生成的测试增加了与未经修改的功能测试未执行的错误处理代码相关的覆盖率。
-
Time w/DR:表示启用动态缩减的执行时间。
-
TG Overhead:表示生成测试的总开销时间。
Dynamic Reduction
当应用程序以服务图的深度而不是广度的方式构建时,应用程序可以从动态缩减中显着受益,例如Audible就是服务调用关系具有一定的深度。
Mocks
实现语料库时,作者为每个示例中的每个服务编写了单元测试,使用模拟来解释可能的远程服务故障。 在编写这些测试时,只测试了独立的故障。
如图 2 的 Audible 下载服务,其单元测试包含一个模拟三个依赖项的失败:Ownership、Active和State。在这里省略了服务特定故障的列表,请读者参考图表获取列表。
同时为Timeout和ConnectionError这两个异常分别编写了一个模拟。
不足和未来工作
- 语料库中的示例用HTTP 服务取代了真实云服务和数据库的使用,但在实际生产环境中,服务间的通信方式还包括如gRPC等多种服务通信。作者已经开始努力通过 gRPC 支持和对 AWS DynamoDB 和 AWS RDS 等云服务的支持来扩展系统原型。
- 该设计不考虑服务响应的损坏,而是关注假设的响应或指示失败的响应。
- 系统中将返回错误码就看作请求失败,但是在生产环境中,往往对一些错误响应会给出处理。在某些情况下,可能会提示开发人员编写异常处理程序和其他条件错误处理,以处理实际上可能不会在生产中发生的故障。
- 动态缩减在微服务依赖呈现更大的调用深度时表现更好,广度更大时难以起到明显的作用。