来源:ACM SoCC'21
概述
-
解决了什么问题:提出一个微服务资源调度框架,解决微服务的调度问题,具体来说从水平扩缩容——增减服务实例和垂直扩缩容——控制每个服务CPU和内存等资源的配额两个维度对微服务进行调度
-
适用于什么环境:该资源调度框架应用于使用K8s部署的微服务上
-
实验的实施和结果:使用多个微服务应用和现实世界中的负载情况进行实验,资源利用表现提高22%,用户端到端实验降低20%
-
目标和宗旨:找到一个最佳资源分配大小,保持良好服务质量的同时尽可能提高资源利用率,减少资源配额
微服务调度存在的问题和挑战
- 确定微服务应用对资源的需求是个复杂工作,难以预先确定
- 如果分配过多的资源会造成集群资源利用率低,增加开销
- 分配资源过少则导致服务性能下降甚至服务不可用,带来更严重的问题
贡献
- 垂直和水平扩缩容框架,旨在提高资源分配的效率
- 调度亲和性和反亲和性规则,为K8s调度程序生成更好的微服务调度规则,提高调度效率
- 实现上述要点并评估
设计思路
概述
- 垂直扩缩容:参照历史资源利用率来寻找每个微服务的最佳资源配额,调度的资源是每个服务占用的CPU、RAM、Disk等资源
- 水平扩缩容:使用Linux内核线程调度程序队列的指标(如eBPF runq latency)为扩缩容指标,同时利用控制理论的思想,在微服务运行时对实例数量进行控制。并设计了一个proportional-integral-derivative控制器,利用历史扩缩容操作和当前的运行时状态来做出下一个水平扩缩容决策,并保持服务的稳定,调度的资源是增减服务实例数量
- 服务间依赖:同时考虑了服务间依赖关系,优先调度应用中负载压力大的微服务(如某个微服务作为其他微服务的引用)
- 服务性能:在找到一个最佳配额后,会协助集群调度微服务以获得更好的端到端性能
- K8s亲和性与反亲和性:通过不同微服务的历史资源使用情况为K8s生成调度规则(如某种微服务和某类资源有正相关性或负相关性)
- 调度效率:能够快速适应工作负载变化
垂直扩缩容
-
调度依据指标:实例的历史资源使用情况(CPU、RAM、Disk、Network等)
-
需要达成的效果有:
- 在运行时为服务找到合适的资源需求
- 最大限度减少过度配置导致的资源使用松弛(松弛度=资源配额-资源使用量)
- 最大限度减少OOM错误和CPU负载过高的情况,保证服务质量
-
垂直扩缩容的局限:每个实例的资源占有量最大不会超过虚拟机的资源量,所以某些情况下即使将虚拟机的所有资源都给到实例也难以满足要求,这就需要水平扩缩容
水平扩缩容
- 调度依赖指标:eBPF指标数据
eBPF:允许在内核级别允许安全和低开销的程序,从内核级别收集准确的事件信息,如CPU调度程序决策事件、内存分配事件和网络堆栈中的数据包事件。已经被广泛用于微服务检测、性能提升、链路追踪、负载均衡、网络监控和安全中。
具体思路
垂直自动扩缩容
K8s(Google Autopilot也是类似)通过检测一段时间窗口(几分钟到几天)中的CPU和内存使用量来设置下一个事件窗口中的资源。通过一个margin和观测到的如P95、P99的百分位值,目的是为资源增加一些宽裕度,尽可能减少OOM错误和CPU不够用的情况发生。作者认为这还不够节约,存在资源浪费的情况发生。$\alpha$为宽限额度,$\pi$是某个测量的百分位数值。

而SHOWAR使用“three-sigma”经验法则去分配资源。
- SHOWAR收集持续时间W秒的最后一个窗口的每种资源使用的统计数据,每秒收集一次,用于递归计算该窗口上的资源使用平均值$\mu$和方差$\sigma^2$。
- 计算$s=\mu + 3\sigma$,这里$s$就是特定资源的一个估计量
- 然后每经过T秒(T « W)评估资源使用量是否发生了很大的变化(如超过15%),一旦超过预期值就实施资源重新分配。

作者认为使用百分数值的3-σ法则能在保证服务良好运行的情况下最大限度的减少资源浪费,同时使用一个阈值来决定是否进行资源重新分配操作能在资源使用差异较小时不会过度配置资源。虽然$\mu+3\sigma$和$\pi(1+\alpha)$都有明确的统计解释,但是使用$3\sigma$可以更加准确的看到均值的分布。如果方差非常小,则分布几乎是恒定的,这是关于 Pod 资源使用情况的单独有用信息。然而,在$\pi(1+\alpha)$方法中,当方差非常小时,尾部百分位数不能传达有用的信息。此外,安全宽裕度参数 $\alpha$的选择可能是任意的,如果未正确指定,可能会导致资源利用率低下或更多OOM错误。
关于P90、P95等百分位数值的补充资料:https://www.cnblogs.com/hunternet/p/14354983.html
水平自动扩缩容
水平自动扩缩容目前存在一些缺陷:
- 由于水平扩缩容的主要形式是通过增减服务实例数量来调整资源分配,服务实例在遇到负载激变发生资源使用抖动时,可能导致极端过度配置或者配置严重不足。为了解决这种情况,有些自动缩放策略引入冷却期的概念,在最后一次操作之后的一段时间内不进行扩缩容。如果出现瞬时负载峰值过高的情况也会因为处于冷却期而避免不必要的扩容操作。
- 系统不会将系统微服务的依赖关系考虑在内,而是单独处理某个微服务。实践表明在不考虑微服务相关性的前提下的资源分配和缩放效率低下,并且不一定有助于应对负载变化和保证服务质量。如下图对某个后端服务在5s时注入高负载,然后经过一段时间,后端的高延迟情况传到了前端,如果考虑微服务间依赖关系,那么仅扩容后端微服务就可以解决这个问题。

- 以往通常使用CPU利用率作为缩放指标,力求在所有微服务中保持目标 CPU 利用率。但CPU 利用率并不是自动缩放和资源分配的最有效指标,随着负载的增加,几乎所有微服务的 CPU 利用率都会增加,而上图的前端微服务的尾部延迟并不总是随着 CPU 利用率的增加而增加(主要是由于后端微服务的高延迟导致的)。
SHOWAR旨在解决上述问题,使用控制理论基本框架来设计有状态的水平缩放系统,在满足SLO指标下保证服务稳定。
通过观测值与目标值的差别来控制缩放是不准确的:$e=observation-target$,为此作者设计了更复杂的控制器pro-portional–integral–derivative (PID) controller:

对资源的检测使用我们使用eBPF Linux调度程序runq 延迟度量,它表示线程可运行与获取CPU并运行之间的时间。使用Runq延迟的P95作为目标点。与CPU利用率不同,高runq延迟与每个单独的微服务的高请求尾延迟高度相关,这表明runq延迟可以用作水平自动缩放的合适指标,以防止请求延迟增加。直观地说,runq延迟优于CPU利用率的原因是它表明应用程序线程如何竞争CPU资源,因此需要更多(或更少)的CPU资源。在SHOWAR中,使用者要指定目标runq的延迟值作为配置的一部分。
水平扩缩容的传递函数很简单,如果runq超出目标值,则系统必须向外扩展并增加副本数量,反正小于目标值则缩减服务实例(这里目标是是一个范围?我是这么认为的)。为了防止执行过多的自动缩放操作以响应 runq 延迟指标中的快速变化和瞬时突发性,作者在目标周围设置了一个可配置的界限$\alpha%$(默认为 20%)作为缓冲区并且不执行自动缩放操作。自动缩放的增加或减少量是微服务当前副本数量的可配置 𝛽 百分比(默认为 10%),如果实际缩放副本数小于1则默认是1(我的理解是,如该实例有20个副本,则扩容20×0.1=2个副本,如果是4个副本4×0.1=0.4<1即扩容1个副本)。算法如下:

水平自动扩缩容的两种架构:
- One For All:单个控制器负责自动扩展所有微服务类型。在每个自动缩放决策中,所有微服务都会根据所有微服务中当前度量值观察的平均值一次缩放。虽然这种方法受益于 PID 控制器,但它没有考虑微服务的微服务依赖关系图。
- One For Each:控制器负责每个微服务。每个控制器监控其相应微服务的自动缩放指标runq,根据上述算法进行缩放。控制器输出的绝对值被排序,具有最高值(最大扩展需求)的那些被优先考虑。对于相等的控制器输出,我们会考虑微服务的依赖关系图,并将后端服务优先于依赖的前端服务(在图的拓扑排序之后)。
将二者串联
在K8s等部署平台上推荐的方法是:一次部署仅使用一类缩放器(如为每个微服务确定固定的实例数量的前提下,部署垂直缩放器,自动调整每个实例的资源分配量;或是确定好资源分配量后,令服务通过水平缩放器自动进行实例数量的增减)。
SHOWAR通过允许串联部署这二者。首先,作者将任何垂直自动缩放决策优先于任何水平自动缩放决策。因为,例如在内存自动缩放的情况下,如果 Pod 的内存不足,应用程序会遇到OOM错误并停止执行,而不管其副本数如何,所以水平自动缩放器无法解决OOM问题。因此,在水平自动缩放控制器动作之前,它首先检查共享通道以查看该微服务是否正在进行垂直自动缩放,如果是则不会继续操作。类似地,在垂直Pod自动缩放器动作之前,它会通过共享通道发送消息通知水平自动缩放器,然后执行其操作。
此外,由于谷歌云平台的 Kubernetes 最佳实践,建议大多数 Pod 不需要超过一个核心,作者根据这个建议将其合并到 SHOWAR 的垂直自动缩放器设计中:如果垂直自动缩放器决定为 Pod 设置多个核心,它会改为通过共享通道向水平自动缩放器发出信号,并且不会继续执行垂直自动缩放操作。即:核心数增加转化为实例数量增加。
利用K8s亲和性和反亲和性获取更好的调度性能
关于K8s的亲和性和反亲和性可以概括为:服务𝑆2与服务𝑆1的亲和性意味着调度程序将始终(或最好)尝试将服务 𝑆1 的 Pod 调度到服务 𝑆2 所在的节点上。类似地,服务𝑆2与服务𝑆1的反亲和性意味着调度程序永远不会(或最好不)这样做。
SHOWAR监控和使用微服务的历史(即最后(可配置)时间窗口)CPU、内存和网络使用情况,并计算每对微服务使用模式之间的Paerson相关系数来计算相关性:给定两种微服务类型𝑋和𝑌的CPU(或内存或网络I/O)使用分布,𝑋和𝑌之间的相关系数$\rho$为:

对于两个微服务𝑆1和𝑆2,资源使用模式(例如CPU或内存)的正相关性越高,它们之间对该资源的资源争用就越高。同样,负相关越低,两个服务之间对该资源的争用就越低。这是 SHOWAR 对 CPU、内存和网络 I/O 等计算资源的亲和性和反亲和性规则的简单基础。
进一步产生亲和性和反亲和性规则,规则生成机制如下:
- CPU和NetWork:如果两个服务s1、s2的CPU和网络是用呈现强负相关($\rho_{s1s2}\leq-0.8$),则为其生成亲和性规则。
- Memeory:如果任何一对微服务s1和s2在它们的内存使用模式中具有强正相关(例如$\rho_{s1s2}\geq-0.8$),则SHOWAR 为调度程序生成s1和s2的反亲和性规则。(实际上也是负相关$\Longrightarrow$亲和性)。
- 此外,为避免调度冲突,每个微服务在任意时间最多参与一个亲和性或反亲和性规则。
实现
系统架构
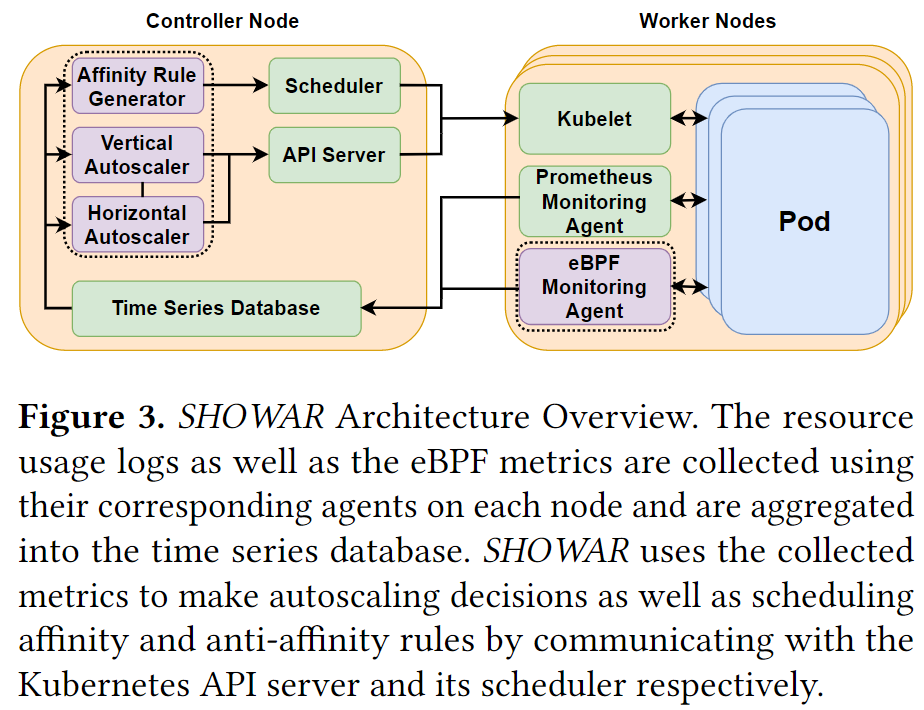
Monitoring Agents
使用Prometheus从节点和容器收集不同的指标。通过集群中的每个节点上启动一个监控代理来收集容器指标,例如CPU使用率、内存使用率、网络带宽使用率等。代理被配置为每秒收集和报告一次指标。Prometheus附带一个时间序列数据库,代理存储收集到的指标。此外,还提供了一种查询语言来查询其他模块使用的时间序列数据库以利用收集的指标。
此外作者还开发了一个eBPF程序作为监控代理部署在集群中的每个节点上,以收集水平自动缩放器使用的 runq latency指标。该指标是每个Pod的CPU线程在获取CPU之前所经历的延迟的直方图。程序每 1 秒收集一次runq latency直方图,并将其存储在Prometheus时间序列数据库中。
The Vertical Autoscaler
- 垂直自动缩放器是一个简单的循环,每分钟发生一次。
- 它会在前5分钟的窗口中为每种资源类型r(CPU和内存)评估$s_r = \mu_r + 3*\sigma_r$,如果s的值变化超过 15%,它会更新服务的资源需求s。
- 触发垂直自动缩放器的另一个条件是微服务报告 OOM 错误。
- 在应用微服务的新资源需求之前,垂直自动缩放器通过共享通道向水平自动缩放器发送一条消息,以不继续任何水平自动缩放操作,因为垂直自动缩放操作优先于水平自动缩放。
- 如果微服务的CPU数量超过一个CPU核心,垂直自动缩放器也不会继续执行微服务的自动缩放操作,在这种情况下,它会通过另一个共享通道向水平自动缩放器以触发水平自动缩放操作。
The Horizontal Autoscaler
对于给定的目标runq latency,它对该微服务执行水平自动缩放操作,使其始终具有目标值的runq latency。控制器每1分钟决定eBPF程序收集60个度量直方图实例(每秒1个)。对于每个直方图,选择第 95个百分位数,控制器使用这60个数据点的平均值作为其当前观察值(也称为测量值)来执行其控制动作。每个水平扩展操作添加或删除至少1个或可配置百分比(默认为 10%)的微服务当前副本数,分别用于扩缩容。
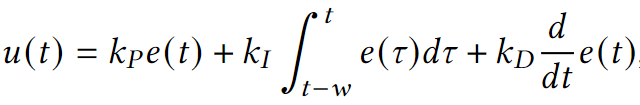
PID控制参数的初始值取为$k_P=k_I=k_D=1/3$(每个参数限制为∈[0,10],这几个参数会影响控制器的速度、稳定性和准确性)。这些参数的增量变化是 10%(我们通过实验发现 10% 可以提供非常好的性能)。控制器输出的波动是进行此类更改的基础,使用之前的N =10个样本进行测量。此外,控制器的“速度”被测量为达到区间[target(1 − 𝛼), target(1 + 𝛼)] 所需的迭代次数,因为 𝛼 =10%。
- 增加$k_P$会导致控制器速度执行增加(以达到稳定状态),同时过高的值可能引发不稳定性。
- 增加$k_I$也会增加控制器的速度并可能导致不稳定,但增加它会降低控制器的噪声(变化和波动)和稳态误差。
- 增加$k_D$会增加控制器的速度(达到稳态)以及不稳定的可能性,同时会显著放大控制器的噪声。
- 控制器从系数的相等值开始。
- 随后这些系数基于监控的工作负载性能和控制器状态进行自适应和增量自调整。
- 如果当前指标值(尤其是runq延迟)远离目标指标值,则在每次迭代中增加$k_P$和$k_I$,以提高稳定性以及达到目标指标值的速度。
- 此外,如果观察到度量值的波动(在控制器中称为噪声),$k_D$会逐渐减小以减少工作负载突发性引入的噪声。
The Affinity Rule Generator
亲和性规则生成器每5分钟使用一次CPU、内存和网络利用率,这是一个由300个数据点组成的向量(每个数据点是微服务副本的平均值)来计算每个资源类型之间的相关系数一对微服务。为消除弱相关或无相关实例,[−0.8,+0.8]中的任何值都会被丢弃。其他强负相关和强正相关的微服务用于生成亲和性和反亲和性规则。资源使用模式会随着工作负载的变化(也称为工作负载转移)而变化,因此如果在随后的5分钟时间窗口内强烈的负相关或正相关变化超过20%(可配置),SHOWAR会撤销亲和性(或那对微服务的反亲和性)规则。
其他要点
SHOWAR是作为Kubernetes控制器构建的,对于自动扩缩器和其他类型的控制器具有高度可插入性。此外,SHOWAR使用常用的Kubernetes监控代理(例如Prometheus)和一个自定义的eBPF指标监控代理。因此,与默认的Kubernetes自动缩放器相比,SHOWAR不会引入任何额外的开销。此外,自动缩放器被调度在控制器节点上,并且不与调度在工作节点上的应用程序 Pod 共享资源。
实验
在AWS部署K8s集群,用Google Autopilot和K8s默认的调度程序作比较。资源利用率提升22%,延迟降低20%。
实验设置
Applications
- 社交网络应用:包含36个微服务,可以关注他人、撰写帖子、阅读他人帖子并与之互动。
- 火车票应用:包含41个微服务的应用程序,允许其用户在线预订门票并进行支付。
- 谷歌云平台的线上精品店:由 10 个微服务组成,用户可以通过他们的在线购物车购买在线商品并进行支付。
实验将runq延迟的目标值设置为15𝑚𝑠,即 Linux 内核 sysctl_sched_latency[31] 调度程序参数的 2.5𝑥。
Cluster Setup
- 在AWS上进行的。
- 使用 𝑚5.𝑥𝑙𝑎𝑟𝑔𝑒 VM 实例,每个实例具有 4 个 vCPU、16 GB 内存和 0.192 美元/ℎ𝑟 价格。
- 运行Ubuntu 18.04 LTS,配置为支持运行eBPF程序。
- 除非另有说明,否则集群都是由25个VM实例组成。
Workload and Load Generation
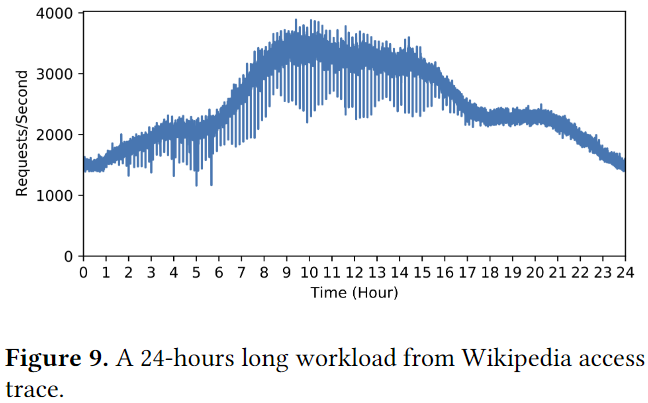
我们使用Wikipedia访问跟踪[59]作为我们的主要工作负载。它是用户与Wikipedia网站交互的真实世界轨迹,由流量模式组成,包括泊松到达时间、短期突发性和昼夜水平变化。由于我们正在评估的微服务是面向用户的应用程序,因此工作负载必须反映真实的用户行为。因此,维基百科访问跟踪非常适合我们的评估。我们以分布式方式使用locust [26]作为我们的工作负载生成器。 Locust客户端驻留在与托管应用程序的主集群不同的VM实例上。
Baselines
Kubernetes默认自动缩放器和 Google Autopilot。
Vertical Autoscaling
首先评估 SHOWAR 的垂直自动缩放器(禁用水平自动缩放器)在减少相对内存松弛方面的有效性。
使用来下图中所示的 Wikipedia 访问跟踪的一小时长的工作负载进行评估。
每5分钟记录一次垂直自动缩放器为每个微服务设置的内存限制以及微服务的实际使用情况,以计算其内存使用松弛(即松弛 = 限制 - 使用)。
下图描绘了社交应用所有微服务相对内存使用松弛的累积分布函数(the cumulative distribution function,CDF)。
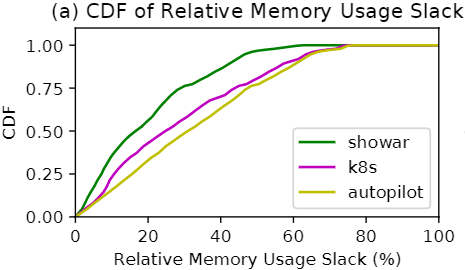
可以看出,通过历史资源使用的变化(使用3-σ规则),SHOWAR 的垂直自动缩放器与Autopilot 和 Kubernetes 的垂直自动缩放器相比能够改善内存使用松弛度。特别是,对于95%的服务实例,相对内存使用松弛率小于46%,而 Kubernetes 和 Autopilot 分别为 63% 和 66%。这 20% 的内存使用松弛可用于调度更多的服务实例或在集群中使用更少的 VM 资源,这将明显降低成本(见 5.5 小节)。我们还观察到 Kubernetes 的性能优于 Autopilot,因为它在设置限制方面采用了更激进的方法(使用 P95 × 1.15 的过去使用量与最大值相比)。
虽然低内存或 CPU 使用松弛可以导致高效且具有成本效益的资源分配,但它可能导致更高的 OOM 率或 CPU 节流,从而降低服务性能。下图显示了实验过程中 OOM 的数量。可以看出,虽然与 Kubernetes 相比,SHOWAR 的 OOM 数量相当,但与 Autopilot 相比,它们在内存扩展方面的激进方法导致了更多的 OOM。

下图则描绘了在实验过程中微服务的平均 CPU 节流(CPU 紧松弛的结果)。当 Pod 的 CPU 使用率超过其分配的 CPU 资源时,容器运行时(使用𝑐𝑔𝑟𝑜𝑢𝑝𝑠)会限制 Pod 的 CPU 份额。可以看出,由于微服务 CPU 使用率的高波动(方差),SHOWAR 的 CPU 节流与基线相当。
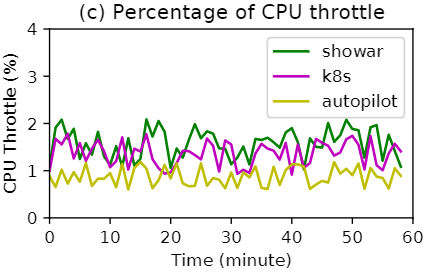
根据以上三图的分析,资源松弛度(也反映了资源使用效率)和系统稳定性之间存在权衡。SHOWAR和K8s在带来更好的资源效率的同时回不可避免的导致更多的OOM错误和CPU性能限制。而 Autopilot 会导致更多的松弛和更少的 OOM。
因此,根据任务目标可调整 SHOWAR 和 Kubernetes 以实现更高的稳定性,但代价是更高的资源使用松弛度。例如,在 SHOWAR 中,可以使用 𝑘𝜎 代替 3𝜎 ,其中 𝑘 >3 为单个 Pod 分配更多资源并减轻 OOM 和 CPU 节流。
Horizontal Autoscaling
使用垂直扩缩容相同的工作负载来评估水平扩缩容。将 SHOWAR 的 One for Each 和 One for All 设计与 Autopilot 和 Kubernetes 水平自动缩放器进行比较。Autopilot 和 Kubernetes 在水平自动缩放中使用相同的方法。我们将 Autopilot 和 Kubernetes 的目标 CPU 利用率设置为 65%,这是通常的建议。
下图描绘了在实验过程中社交网络应用程序中微服务副本数量的累积分布函数。我们观察到 SHOWAR 的水平自动缩放器都优于 Autopilot 和 Kubernetes 水平自动缩放器,因为它为大多数微服务分配了更少的副本,这反过来又可以更有效地分配资源并节省成本(见 5.5 小节)。通过为每个微服务定制一个控制器,SHOWAR 的 One for Each 设计也优于 One for All。这是因为在 One for All 设计中,单个控制器尝试使用单个目标 runq 延迟值和跨所有微服务的平均 runq 延迟测量来扩展微服务,这会导致不必要的微服务扩展和高 runq 延迟。
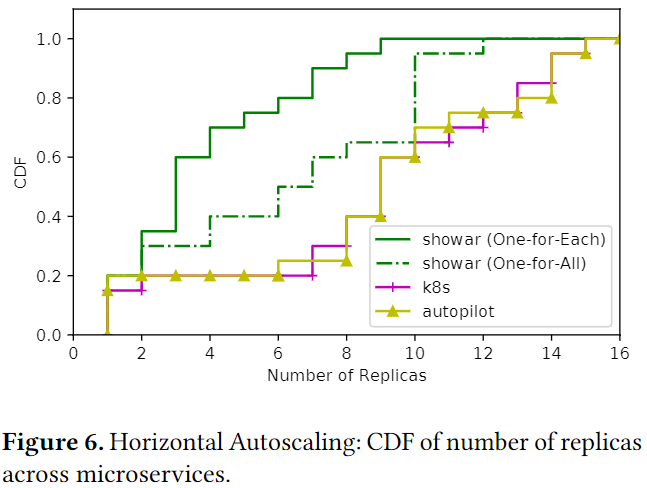
再次强调,SHOWAR 的有效性是由于:
- 自动缩放器的状态控制器
- 用于自动缩放决策的更好的代表性指标(即 runq 延迟而不是 CPU 利用率)
我们看到了在单个微服务的自动扩展决策中使用更有意义和代表性的指标的效果。特别是,在评估过程中,我们观察到 Kubernetes 和 Autopilot 通常为 nginx 设置 16 个副本,这主要是因为它的 CPU 利用率很高。但高 CPU 利用率并不总是对应于微服务性能的大幅提升。相比之下,SHOWAR 只为这个微服务设置了 10 个副本。另一方面,对于其他几个微服务所依赖的 User 微服务,Kubernetes 和 Autopilot 通常只为其设置 3 个副本。相比之下,SHOWAR 通常为此微服务设置 6 个副本。
The Effect of Affinity and Anti-Affinity Rules
实验使用不同微服务之间 CPU、内存和网络 I/O 使用率的相关性来评估 SHOWAR 生成的 Pod 亲和性和反亲和性规则的效果。仍使用相同的工作负载并禁用垂直和水平扩缩容控制器,以凸显亲和性和反亲和性生成器的工作效果,以此观察K8s调度器受其的影响。
同时观测了这如何影响端到端请求延迟,如下图所示。通过为调度程序提供调度提示(使用亲和性和反亲和性),SHOWAR 能够改善用户体验的 P99 延迟。特别是,使用 SHOWAR 生成的亲和和反亲和规则,请求延迟的 P99 为 6600 毫秒,而使用 Kubernetes 默认调度决策为 9000 毫秒。

End-to-End performance
在端到端性能评估这部分使用三个组件协同工作,使用下图的工作负载进行测试。为了适应工作负载,我们将集群的大小增加到 30 个 VM 实例。结果表明,与基线相比,SHOWAR 改进了资源分配和利用率,同时保持性能的稳定。
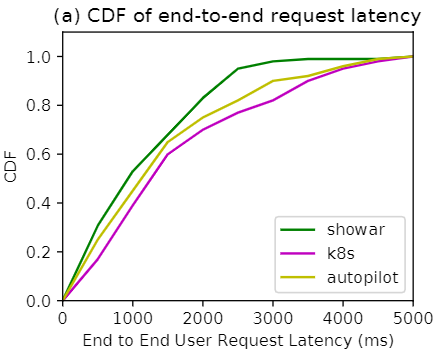
下图描述了用户在实验的 24 小时内经历的端到端请求延迟的 CDF。可以看出,使用 SHOWAR 的端到端性能与基线相当,并且使用其亲和性和反亲和性规则生成器以及依赖关系感知的水平自动缩放,与 Autopilot 和 Kubernetes 相比SHOWAR 能够将 P99 延迟提高 20% 以上。 Autopilot 和 Kubernetes 在 P99th 延迟方面表现出相似的性能,但是,由于为副本分配了更多内存,Autopilot 通常在较低的尾部优于 Kubernetes。
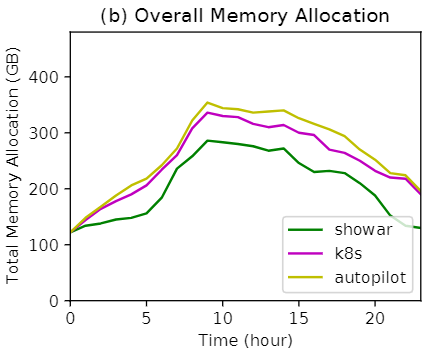
下图显示了实验过程中集群中的总内存分配(即为微服务副本设置的内存限制总和)。与基线相比,SHOWAR 平均为微服务副本分配的内存更少。特别是,SHOWAR 平均分配了 205 GB,而 Autopilot 和 Kubernetes 分别分配了 264 GB 和 249 GB。主要是因为 SHOWAR 的垂直自动缩放器实现了较低的内存使用松弛度,并且其水平自动缩放器为微服务设置了较少的副本数量。因此,使用 SHOWAR 的总内存分配小于基线。
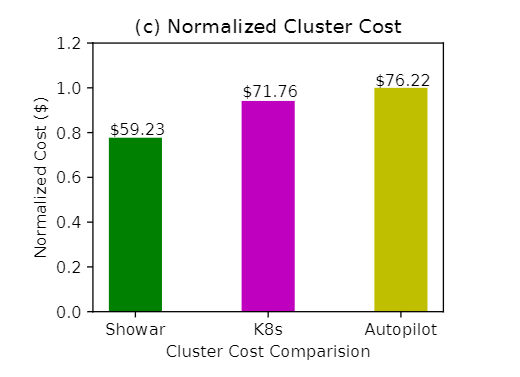
最后,在下图中,展示了每个实验的归一化集群成本。我们将平均内存分配标准化为集群中一台虚拟机的内存大小(即 16 GB 用于𝑚5.𝑥𝑙𝑎𝑟𝑔𝑒 实例),并将其乘以 24 小时内一台虚拟机的成本(即 $0.192/ℎ𝑜𝑢𝑟)。这是因为,通常虚拟机在公共云上的价格是内存大小的线性函数 [17]。可以看出,与 Autopilot 和 Kubernetes 相比,SHOWAR 将集群总成本效益分别提高了 22% 和 17%。这些改进来自这样一个事实,即与基线相比,SHOWAR 的垂直和水平自动缩放器用分配更少的计算资源就可以达到相同的性能和服务质量。
不足和未来工作
-
SHOWAR是基于历史和现在进行反应式调度的,缺乏预测能力
我们将 SHOWAR 设计为计算量轻且适应性强,这与使用需要训练且无法应对工作负载转移的机器学习的“黑盒”方法形成对比,例如 [39,55,57]。然而,目前 SHOWAR 的一个主要限制是它对微服务的资源使用是反应性的。因此,一个合适的探索途径是为 SHOWAR 配备近期工作负载和资源使用预测,例如 [18]。结合其当前设计,预测近期工作负载可以改善 SHOWAR 的资源分配并防止由于自动缩放操作不足而导致性能下降。
-
另一个限制是它只关注微服务自动扩展并假设一个固定大小的集群
解决应用程序自动缩放器请求的资源总量超过可用集群资源总量的场景非常重要。虽然集群自动缩放与应用程序自动缩放是正交的,但它们需要协同工作以实现资源分配的整体效率和应用程序的性能要求。因此,需要两个自动扩缩器之间的通信和协调才能向集群添加更多资源。在未来的工作中,我们计划改进 SHOWAR 的自动缩放器以与现有的集群自动缩放器 [12] 一起使用。
-
还不适用于Serverless类型的工作负载
原因之一是垂直自动缩放不适用,因为无服务器功能的容器大小是预定义的。 SHOWAR 的水平自动缩放器可能面临额外的复杂性,例如,跟踪“休眠”无服务器函数的数量(可以热启动)以及每个函数“过期”的时间(因此需要冷启动延迟)。我们将探索无服务器功能水平扩展的控制理论方法留给未来的工作。
-
计划改进 SHOWAR 的亲和性和反亲和性规则生成器
目前使用简单的经验资源利用相关系数来确定微服务之间的成对亲和力。例如,我们可以在未来探索其他统计数据对亲和力的影响,例如不同类型资源之间的互相关,并探索不同类型的调度机制,这些调度机制可以直接利用这些“原始”统计信息来提高效率资源利用[19]。