来源:ASPLOS'21 ccf-a
作者:Cornell University
- 正如题目所说,这篇文章主要就是使用机器学习的方法,针对微服务架构的应用进行资源配置,当然是保证QoS的前提下提高资源分配和使用的效率。
- 利用ML方法帮助调度的决策
- 面向以容器和虚拟机构建及部署的微服务应用
问题的痛点是什么?或是要解决什么问题?他们的idea有什么值得学习的地方?
先前的工作
- 为满足QoS而忽视资源利用率,往往有较高的资源分配上限,把边界划定的很远,虽然是为了更好的满足QoS要求但是牺牲了资源
- 针对单体系统而没有考虑微服务架构的特点
本文idea
-
突出QoS、E2E时延
-
资源分配突出了一个满足QoS要求,并且多次提到OOM错误
-
考虑到微服务架构的层级结构(tier)
-
考虑到微服务架构的拓扑图,也就是微服务之间的依赖关系
-
提到了微服务中某些排队队列的环节会因为QoS违规导致更长时间的排队等候,进而提出了需要一个较长时间的预测
具体是什么云环境?应用以什么样的方式部署?
Docker + VM组成的云环境。应用以被打包成Docker镜像然后部署在虚拟机上。
使用了什么机器学习方法?这个学习解决的是什么问题?
文章提出了一个“two-stage model”。第一阶段,使用CNN预测下一个时间步的E2E时延,这对精确性提出了很高的要求;第二阶段,使用Boosted Trees预测QoS违规(需要使用CNN模型的输出)。
第一阶段和第二阶段分别代表了短期和长期的预测结果,以辅助调度的决策。
CNN卷积神经网络
CNN模型主要用于短期的性能预测。
具体来说,使用CNN来预测下一个时间窗口的时延分布,是秒级的窗口(默认是5秒)。但是文章发现,预测时延是件很困难的事情,并且随着预测时间的增加,效果不理想。
因此进一步的,文章将预测策略变为:预测是否出现QoS违规,也就是随后的时间段出现QoS违规的概率。(因为通常将QoS与E2E时延划等号,出现QoS违规相当于E2E时延过长,所以QoS违规给调度决策带来的信息是足够的)
模型使用到的输入数据
- CPU使用信息
- 内存使用信息(包括常驻内存和缓存)
- 网络使用信息(如接收和发送的数据包)
这些都是用Docker cgroup的接口收集。
- 上一个窗口E2E时延的分布
- 能够在下一个时间窗口分配的资源信息
模型的预测输出
- 下一个时间窗口的时延信息,该信息会进一步用于Boosted Tree中
Boosted Tree
增长树模型主要用于长期的性能预测。具体来说,进行一个二分类问题的预测——接下来的资源分配是否会造成QoS违规,通过这个预测来减少未来预期之外的负面影响。
模型使用到的输入数据
- 使用到CNN中的预测输出的时延信息
- 资源分配信息
模型的预测输出
- 在接下来时间步k中,是否会出现QoS违规现象
系统架构是什么样的?如何分配资源?
系统架构
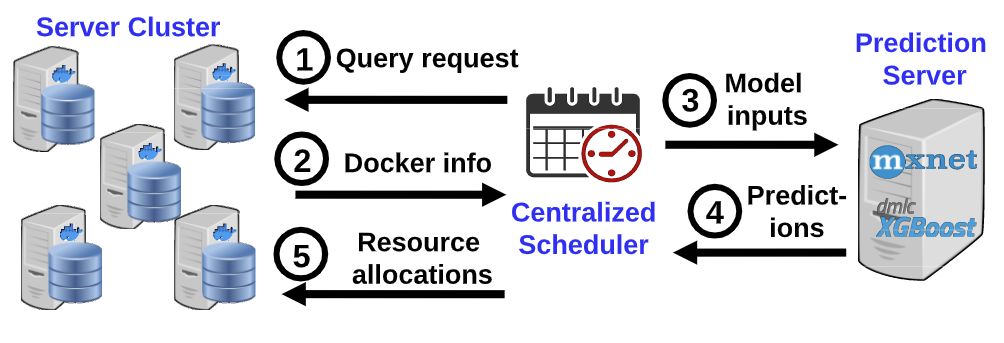
- 中心化的调度器
- 分布式的节点代理
- 单独部署的预测服务
系统流程如上图。
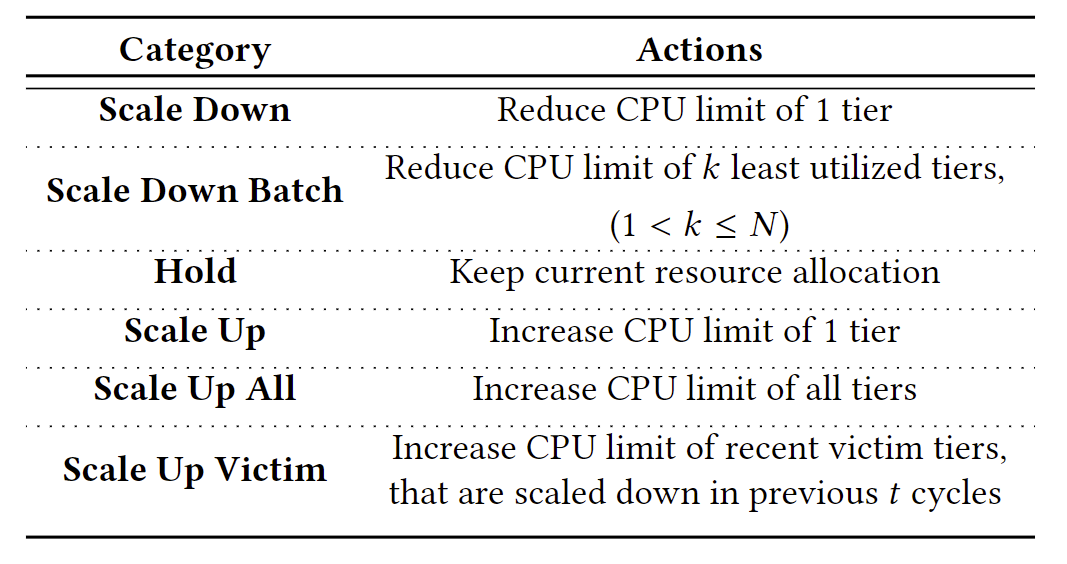
资源分配
系统中资源分配的几种动作如下:
评估怎么做的?使用了什么应用?
- 在本地集群和Google Cloud上面做的实验
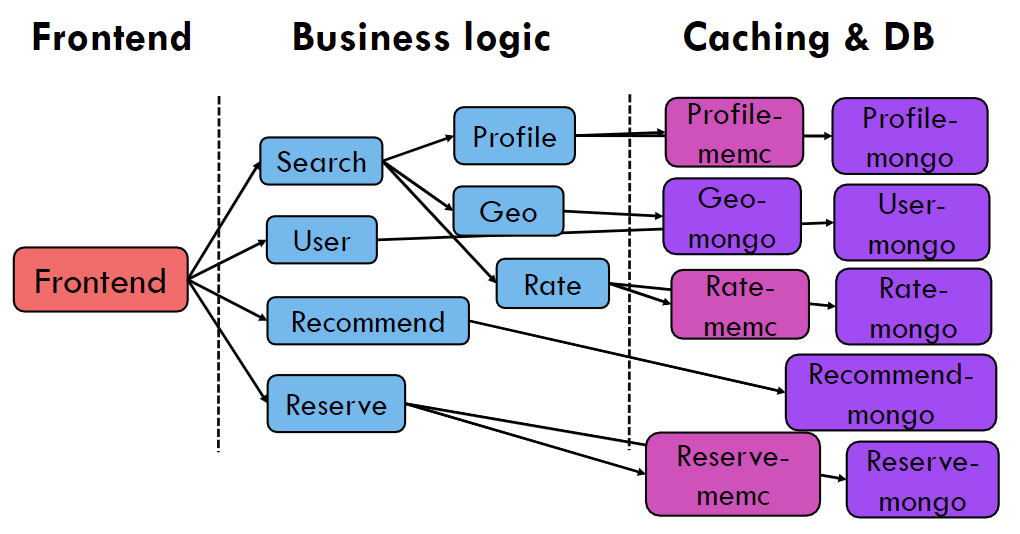
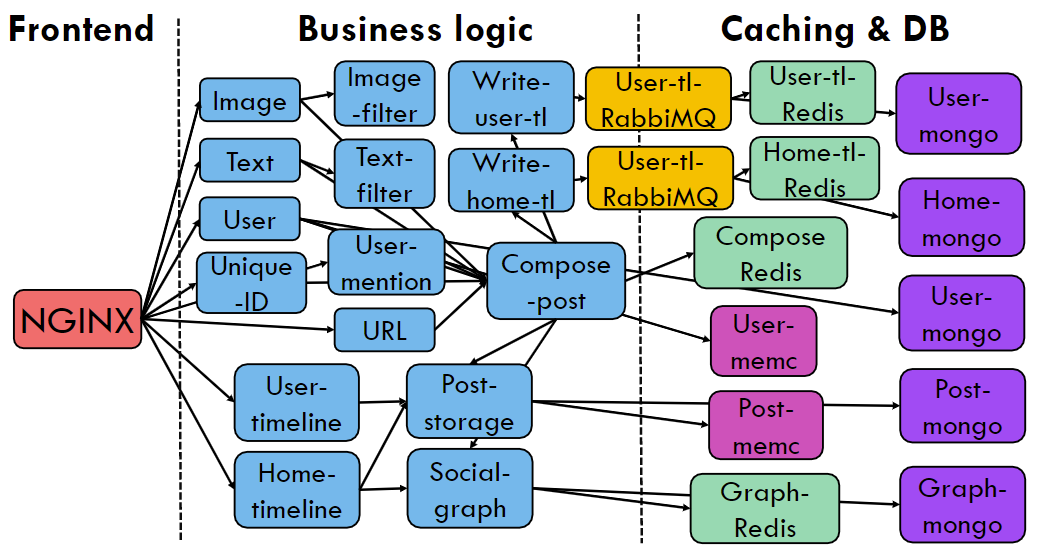
- 使用了微服务benchmark套件DeathStarBench(有论文的这个套件)以及其中的应用Hotel Reservation,Social Network。
- 使用Docker Swarm进行部署
- 收集了31302和58499条Hotel和Social Network的数据
实验环境
- 本地集群:80core CPU/256GB RAM
- GCE集群:93containers
微服务应用
Hotel Reservation
Social Network
做实验时可以参考本文实验设计